ข้อมูลขนาดใหญ่
Big Data
พันเอก มารวย ส่งทานินทร์
10 กรกฎาคม 2558
บทความเรื่อง ข้อมูลขนาดใหญ่ (Big Data) นำมาจากหนังสือเรื่อง Big Data: A Business and Legal Guide ประพันธ์โดยJames R. Kalyvas และ Michael R. Overly จัดพิมพ์จำหน่ายโดยCRC Press, 2015
ผู้ที่สนใจเอกสารนี้แบบ PowerPoint (PDF file) สามารถ Download ได้ที่ http://www.slideshare.net/maruay/big-data-50353153
“ข้อมูลขนาดใหญ่ จะเป็นสาระสำคัญต่อการเปลี่ยนแปลงการตัดสินใจ ของธุรกิจและองค์กร”
ข้อมูลขนาดใหญ่ สำหรับผู้บริหาร
-
บทความนี้ เป็นการอธิบายคำว่า ข้อมูลขนาดใหญ่ (Big Data) ในภาษาคนธรรมดา (จากมุมมองของคนไม่มีความรู้ด้านเทคนิค) ถึงลักษณะที่แตกต่างจากข้อมูลขนาดใหญ่ กับรูปแบบฐานข้อมูลแบบดั้งเดิม ว่า
- 1. อะไรคือข้อมูลขนาดใหญ่? และลักษณะของข้อมูลขนาดใหญ่ (ปริมาณ ความแตกต่าง ความเร็ว และการตรวจสอบ)
- 2. แนวคิดการทำงานข้ามสายงาน ทักษะใหม่ และการลงทุน
- 3. วิธีการแสวงหาข้อมูลที่เกี่ยวข้อง
- 4. พื้นฐานของการทำงานด้านเทคโนโลยีของข้อมูลขนาดใหญ่
+++++++++++++++++++++++++++++
เกริ่นนำ
- ทุกวันนี้ มีการหารือถึงความสำคัญที่เพิ่มขึ้นและเร่งด่วน ของ "ข้อมูลขนาดใหญ่" (Big Data) ในห้องประชุมคณะกรรมการบริหาร การประชุมเชิงกลยุทธ์ และการดำเนินงานอื่น ๆ ขององค์กรทั่วโลก
- มีข้อสังเกตว่า ผู้บริหาร ผู้จัดการ และที่ปรึกษา อาจจะมีความเข้าใจที่แตกต่างกันมาก ในสิ่งที่เป็นข้อมูลขนาดใหญ่ เมื่อเทียบกับนักเทคโนโลยีและนักวิทยาศาสตร์ข้อมูล ที่อยู่ในองค์กรของพวกเขา
- ความเข้าใจที่แตกต่างกันเหล่านี้ มาจากการขาดคำนิยามที่ได้รับการยอมรับของข้อมูลขนาดใหญ่ ทำให้เกิดความเข้าใจร่วมกันน้อยมากระหว่างผู้บริหาร ผู้จัดการ และที่ปรึกษา ที่ไม่ได้มีส่วนเกี่ยวข้องกับเทคโนโลยีการทำงานของข้อมูลขนาดใหญ่ในชีวิตประจำวัน
1. อะไรคือข้อมูลขนาดใหญ่?
- ข้อมูลขนาดใหญ่ เป็นกระบวนการส่งมอบข้อมูลเชิงลึกที่ใช้ในการตัดสินใจ โดยการใช้คนและเทคโนโลยีวิเคราะห์ข้อมูลจำนวนมากที่แตกต่างกัน ได้อย่างรวดเร็ว (ของข้อมูลที่มีโครงสร้างแบบดั้งเดิม และข้อมูลที่ไม่มีโครงสร้าง เช่น รูปภาพ วิดีโอ อีเมล์ ข้อมูลการทำธุรกรรม และปฏิสัมพันธ์สื่อสังคม) จากความหลากหลายของแหล่งที่มา ในการผลิตกระแสความรู้ที่สามารถนำมาใช้ในการดำเนินการได้
นิยามที่ใช้อ้างอิงบ่อย
- "ข้อมูลขนาดใหญ่" หมายถึงชุดข้อมูลที่มีขนาดเกินกว่าความสามารถของซอฟต์แวร์ฐานข้อมูลทั่วไปที่จะ บันทึก จัดเก็บ จัดการ และวิเคราะห์ (McKinsey Global Institute)
- ข้อมูลขนาดใหญ่ คือสินทรัพย์ทางสารสนเทศที่มีปริมาณสูง ความเร็วสูง และความหลากหลายสูง ต้องอาศัยค่าใช้จ่ายที่มีประสิทธิภาพและนวัตกรรมรูปแบบใหม่ของการประมวลผลข้อมูล เพื่อความเข้าใจที่ดีขึ้น และใช้ในการตัดสินใจ (Gartner. IT Glossary. 2013)
ลักษณะของข้อมูลขนาดใหญ่
- ในการอภิปรายของ ข้อมูลขนาดใหญ่ มักมีการอ้างอิงถึง "3 Vs" คือ ปริมาณ (Volume) ความเร็ว (Velocity) และลักษณะความหลากหลาย (Variety) ของข้อมูลขนาดใหญ่
- พูดง่ายๆ คือ ปริมาณ (ปริมาณของข้อมูล) ความเร็ว (ความเร็วในการประมวลผล และการเปลี่ยนแปลงของข้อมูล) และ ความหลากหลาย (แหล่งที่มาของข้อมูล และชนิดของข้อมูล) เป็นลักษณะที่โดดเด่นที่สุดของข้อมูลขนาดใหญ่ ต่างกับวิธีการแบบดั้งเดิมที่ใช้ในการบันทึก จัดเก็บ จัดการ และวิเคราะห์ข้อมูล
ปริมาณ
- ปริมาณของข้อมูล เพิ่มขึ้นอย่างรวดเร็วตั้งแต่ปี 2004 โดยในปี 2004 จำนวนของข้อมูลที่เก็บไว้บนอินเทอร์เน็ตมีทั้งหมด 1 petabyte (1,000 terabytes) เทียบเท่ากับ 100 ปีของเนื้อหาโทรทัศน์ทั้งหมด
- ในปี 2011 จำนวนรวมของข้อมูลทั่วโลกที่เก็บไว้ด้วยระบบอิเล็กทรอนิกส์ คือ 1 Zettabyte (1,000,000 petabytes หรือ 36 ล้านปีของวิดีโอความละเอียดสูง [HD]) โดยในปี 2015 ตัวเลขคาดว่าจะถึง 7.9 zettabytes (หรือ 7,900,000 petabytes)
- ขนาดของชุดข้อมูลที่มีการใช้งานอย่างต่อเนื่อง มีการเจริญเติบโตแซงหน้าความสามารถของเครื่องมือแบบดั้งเดิม ในการบันทึก จัดเก็บ จัดการ และวิเคราะห์ข้อมูล
ความหลากหลาย
- ข้อมูลขนาดใหญ่ เป็นการรวมของข้อมูลที่เก็บไว้ในฐานข้อมูลของ ข้อมูลที่มีโครงสร้างแบบดั้งเดิม (structured databases) และข้อมูลใหม่ที่ทีที่มาจากแหล่ง ข้อมูลแบบที่ไม่มีโครงสร้าง (unstructured data)
- ข้อมูลที่ไม่มีโครงสร้างรวมถึง ข้อมูลที่ไม่ได้มีโครงสร้าง (เช่นFacebook, Twitter, Instagram และTumblr) ที่มีการเติบโตอย่างรวดเร็วของ ภาพ วิดีโอ ข้อมูลการเฝ้าระวัง ข้อมูลจากเซ็นเซอร์ ข้อมูลศูนย์โทรศัพท์ ข้อมูลตำแหน่งทางภูมิศาสตร์ ข้อมูลสภาพอากาศ ข้อมูลทางเศรษฐกิจ ข้อมูลของรัฐบาล รายงานการวิจัย แนวโน้มการค้นหาอินเทอร์เน็ต และ web log files
- ทุกวันนี้ กว่า 95% ของข้อมูลทั้งหมดที่มีอยู่ทั่วโลก คาดว่าจะเป็นข้อมูลแบบที่ไม่มีโครงสร้าง
ความเร็ว
- จำนวนที่เพิ่มมากขึ้นอย่างรวดเร็วของข้อมูลที่ไม่มีโครงสร้าง มาจากตัวเลขของกระแสการเติบโตแบบก้าวกระโดด ผ่านทางอินเทอร์เน็ตอย่างต่อเนื่อง
- ความเร็วของข้อมูลเหล่านี้ จะต้องได้รับการจัดเก็บและวิเคราะห์ ด้วยลักษณะที่ถือว่า เป็นความเร็วของข้อมูลขนาดใหญ่
การตรวจสอบ (Validation เป็น V ที่สี่)
- กลยุทธ์ข้อมูลขนาดใหญ่ขององค์กร จะต้องมี ขั้นตอนการตรวจสอบ (validation step) และมีการหยุดที่เหมาะสมในการวิเคราะห์ เพื่อประเมินผลกระทบต่อกฎหมาย ระเบียบข้อบังคับ หรือภาระผูกพันตามสัญญา ของ
- สถาปัตยกรรมของระบบข้อมูลขนาดใหญ่
- การออกแบบขั้นตอนวิธีการค้นหาข้อมูลขนาดใหญ่
- การดำเนินการบนพื้นฐานของข้อมูลเชิงลึกที่ได้มา
- การจัดเก็บและการกระจายของผลลัพธ์และข้อมูล
2. แนวทางการทำงานข้ามสายงาน ทักษะใหม่ และการลงทุน
- องค์กรที่ต้องการใช้ประโยชน์จากข้อมูลขนาดใหญ่ในการดำเนินงาน ต้องพัฒนาทีมข้ามสายงานที่มีความรู้ลึกของธุรกิจที่มีการใช้เทคโนโลยี
- องค์ประกอบที่สำคัญของทีมเหล่านี้คือ นักวิทยาศาสตร์ข้อมูล (data scientist) ไม่ว่าจะเป็นพนักงานหรือผู้รับจ้างเหมา เพื่อสกัดข้อมูลเชิงลึกทางธุรกิจของข้อมูลขนาดใหญ่สำหรับองค์กร (เช่น การสั่งซื้อ และความรู้จากความวุ่นวายของข้อมูลขนาดใหญ่)
- นักวิทยาศาสตร์ข้อมูล เป็นนักคิดหลายมิติที่ทำงานได้อย่างมีประสิทธิภาพ ในการพูดคุยเกี่ยวกับปัญหาทางธุรกิจด้วยภาษาธุรกิจ ในขณะที่อยู่ในระดับยอดของเทคโนโลยี การศึกษาสถิติ และประสบการณ์
- นักวิทยาศาสตร์ข้อมูล ไม่ได้เป็นเพียงผู้เชี่ยวชาญเฉพาะเรื่องที่จำเป็นในการออกแบบกลยุทธ์ข้อมูลขนาดใหญ่ แต่มีบทบาทสำคัญที่จะทำงานร่วมกับผู้เชี่ยวชาญเรื่องธุรกิจขององค์กร เช่นสถาปนิกและนักวิเคราะห์ข้อมูล ทีมโครงสร้างพื้นฐานด้านเทคโนโลยี ด้านการจัดการ และด้านอื่น ๆ ที่จะส่งมอบข้อมูลเชิงลึกของข้อมูลขนาดใหญ่
3. การแสวงหาข้อมูลที่เกี่ยวข้อง
- องค์กรจะต้องเข้าถึงข้อมูลที่เกี่ยวข้องกับวัตถุประสงค์ ที่พวกเขาพยายามจะให้ประสบความสำเร็จ ด้วยข้อมูลขนาดใหญ่
- ข้อมูลนี้ สามารถนำมาจากแหล่งใด ๆ ก็ได้ รวมทั้งจากฐานข้อมูลที่มีอยู่ทั่วทั้งองค์กร หรือจากระบบจัดเก็บข้อมูลภายใน หรือระยะไกลโดยตรงจากแหล่งข้อมูลสาธารณะบนอินเทอร์เน็ต หรือจากรัฐบาล หรือสมาคมการค้าโดยใบอนุญาตจากบุคคลที่สาม หรือจากข้อมูลของบุคคลที่สาม หรือผู้ให้บริการที่รวบรวมจากระยะไกล และเจ้าของแหล่งที่มาของข้อมูล
4. พื้นฐานการทำงานทางเทคโนโลยีของข้อมูลขนาดใหญ่
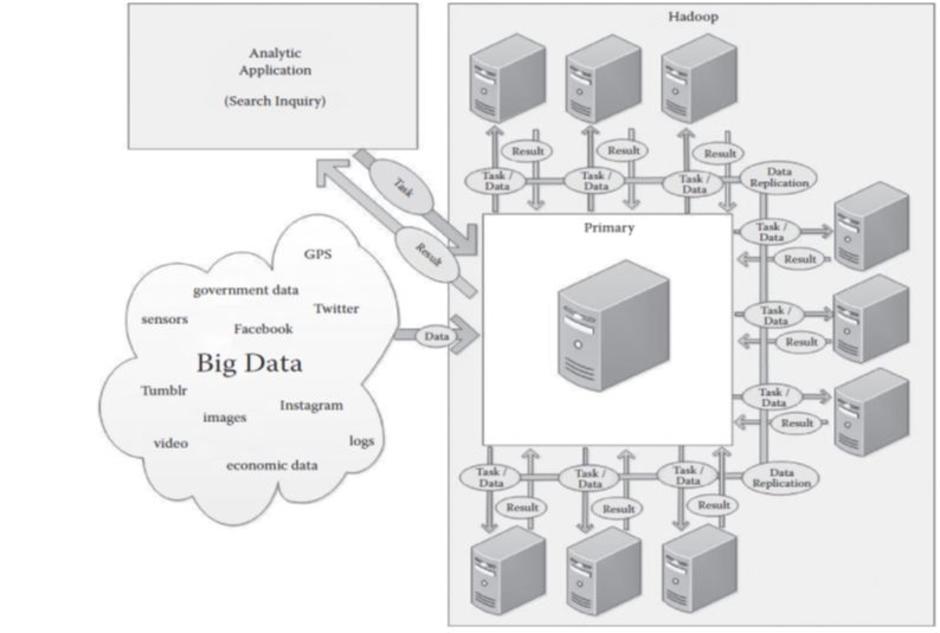
- โดยอาศัยตัวเลขการเติบโตของการแก้ปัญหาแบบเปิด (ที่เปิดเผยต่อสาธารณชนโดยไม่ต้องเสียค่าใช้จ่าย) และข้อมูลขนาดใหญ่บนแพลตฟอร์มการวิเคราะห์ ที่มีอยู่เพื่อผู้ประกอบการ
- Hadoop (ชื่อตุ๊กตาสัตว์ ของเด็กของหนึ่งในผู้สร้าง) เป็นกรอบเปิด (open-source framework) ที่นิยม ประกอบด้วยเครื่องมือซอฟแวร์จำนวนมาก ที่ใช้ในการดำเนินการวิเคราะห์ข้อมูลขนาดใหญ่
- Hadoop จะทำการกระจายข้อมูลที่มีขนาดใหญ่มาก โดยแบ่งออกเป็นชิ้นเล็ก ๆ เพื่อให้มีการจัดการได้ง่ายขึ้น
- Hadoop ทำงานโดยการเชื่อมต่อเครื่องคอมพิวเตอร์จำนวนมากที่มีขนาดเล็กและราคาที่ต่ำกว่าเข้าด้วยกัน ในการทำงานแบบคู่ขนาน เป็นกลุ่มคอมพิวเตอร์ (computing cluster) ที่มีประสิทธิภาพ
- Hadoop จะกระจายข้อมูลโดยอัตโนมัติให้คอมพิวเตอร์ทุกเครื่องในกลุ่ม ดังนั้นจึงไม่มีความจำเป็นที่จะต้องรวมข้อมูลบนเครือข่ายการจัดเก็บข้อมูลแบบพื้นที่ (SAN - storage-area network)
- ในขณะเดียวกันที่ข้อมูลถูกกระจาย บล็อกของข้อมูลแต่ละอัน จะถูกจำลองลงในคอมพิวเตอร์อีกหลายตัวในกลุ่ม
- Hadoop จะย่อยงานเป็นชิ้น ๆ จำนวนมากลงในคอมพิวเตอร์ และโดยการลงข้อมูลที่มีอยู่บนคอมพิวเตอร์หลายเครื่อง เป็นการลดโอกาสที่ข้อมูลไม่สามารถเรียกใช้ได้เมื่อมีเหตุจำเป็น
- แต่ละคุณสมบัติเหล่านี้ จึงทำให้มีประสิทธิภาพมากกว่าเครื่องคอมพิวเตอร์สถาปัตยกรรมแบบดั้งเดิม
- Hadoop คือการรวมกันของซอฟแวร์ขั้นสูงและฮาร์ดแวร์คอมพิวเตอร์ ซึ่งมักจะเรียกว่า "เวที " หรือplatform ที่ทำให้องค์กรที่มีวิธีการดำเนินการแบบ “client application”
- โปรแกรมเหล่านี้ จะมุ่งเน้นไปที่ การเปิดเผยรูปแบบต่าง ๆ ความสัมพันธ์ที่ไม่เคยรู้จักมาก่อน และสารสนเทศที่เป็นประโยชน์อื่น ๆ (uncovering patterns, unknown correlations, and other useful information ) ซึ่งมีอยู่ในข้อมูลขนาดใหญ่ ที่ไม่เคยได้รับการระบุด้วยการใช้แบบจำลองข้อมูลเชิงสัมพันธ์แบบดั้งเดิม
- เมื่อคอมพิวเตอร์ในกลุ่ม ทำการประมวลผลที่ได้รับมอบหมายเสร็จ ก็จะส่งผลลัพธ์และข้อมูลที่เกี่ยวข้องใด ๆ กลับไปที่คอมพิวเตอร์ส่วนกลางแล้วของานอื่นต่อ
- ผลลัพธ์ของแต่ละเรื่องและข้อมูล จะถูกประกอบโดยคอมพิวเตอร์ส่วนกลาง เพื่อส่งกลับไปยังโปรแกรมไคลเอนต์ (client application) หรือเก็บไว้ในระบบไฟล์ของHadoop หรือฐานข้อมูลอื่น ๆ
สรุป
- บทความนี้ อธิบายความหมายของคำว่า ข้อมูลขนาดใหญ่ (Big Data) และอภิปรายเทคโนโลยีที่ซับซ้อน ที่อยู่เบื้องหลังการทำงานของข้อมูลขนาดใหญ่
- แต่จุดประสงค์บทความนี้ ไม่ได้เป็นพิมพ์เขียวสำหรับการสร้างแพลตฟอร์มของข้อมูลขนาดใหญ่ในองค์กร เพียงแต่ให้มีความเข้าใจพื้นฐานร่วมกันว่า ข้อมูลขนาดใหญ่ หมายถึงอะไรเท่านั้น
**********************************
ฺBig Data คำนี้เข้ามาสักระยะและส่วนตัวสนใจกับเรื่องนี้มาก เมื่อประมาณ 2-3 เดือนมานี้ รายการสารคดี ของ NHK (ญี่ปุ่น) ทำเรื่องนี้น่าสนใจมาก เกี่ยวกับการใช้ ข้อมูลขนาดใหญ่ ในโรงพยาบาลแห่งหนึ่งของญี่ปุ่น (เสียดายจดจำชื่อไม่ได้) แสดงให้เห็นทุกขั้นตอนของการใช้ข้อมูล ทั้งซอฟท์แวร์ ฮาร์แวร์ และ พีเพิลแวร์ (หมอเป็นส่วนใหญ่) ผลที่เกิดขึ้น โรงพยาบาลให้การรักษาพยาบาลได้อย่างมีคุณภาพสูงสุด น่าตื่นเต้น และโรงพยาบาลอีกหลาย ๆแห่งน่าจะกำลังมุ่งไปสู่การใช้ข้อมูลขนาดใหญ่
ถ้าโรงพยาบาลในประเทศไทยนำมาใช้บ้างก็จะดี ลงทุนกี่แสนล้านในระยะยาวก็คุ้มมาก ทั้งหมอและคนไข้คงมีความสุขมาก ๆ หรือเขาใช้กันแล้วก็ไม่ทราบ ตอนนี้แพทย์ใช้คอมพิวเตอร์ดูข้อมูลประวัติการรักษาของคนไข้(บางคลีนิคพิเศษ) ก็เพิ่มทั้ง effectiveness and efficiency มากแล้ว แต่ใน รพ. เดียวกันใช่ว่าจะได้ใช้อย่างทั่วถึง ยังมีสิ่งที่ต้องทำ ควรทำอีกมากเหลือเกิน
ในวงการศึกษา ก็คงเรียนรู้แต่นิยามกันไปก่อน แต่จะสัมผัสหรือลงมือทำของจริงกันเมื่อไร การปรับปรุงหลักสูตรที่ไม่ยืดหยุ่นทำให้ใส่อะไรที่ทันยุคทันสมัยเข้าไปได้ช้ามาก
ขอบคุณค่ะที่เขียนเกี่ยวกับเรื่องนี้