(ต่อจาก เรียนสถิติด้วยภาพ ตอนที่ 1 Confidence Interval & alpha level )
เวลาเรามีข้อมูลดิบที่เขาบอกว่า เป็นข้อมูลธรรมดา ความหมายมักจะสื่อว่า การแจกแจงเป็นแบบที่เรียก การแจกแจงปรกติ (normal distribution) ดังรูปบน
รูปแรก บอกว่า ที่ศูนย์กลางเกิดบ่อยแค่ไหน ดูความถี่
รูปถัดมา เกิดให้ดูซะเลย ลงจุดบนเส้น
จะเห็นได้ว่า ลงจุดแบบนี้ ดูยาก
ผมก็เลยจับรูปที่สองมาหมุนรอบตัวเองแล้ว "ถ่ายรูป" เป็นระยะ เวลาซ้อนรูปถ่าย ผมก็จะเห็นเป็นรูปล่าง ที่กระจายเป็นวงกลม

เพราะฉะนั้น ข้อมูลหนึ่งชุด ก็จะเห็นหนึ่งหย่อม
ลองซูมดูให้ชัด ๆ จะเห็นอย่างนี้
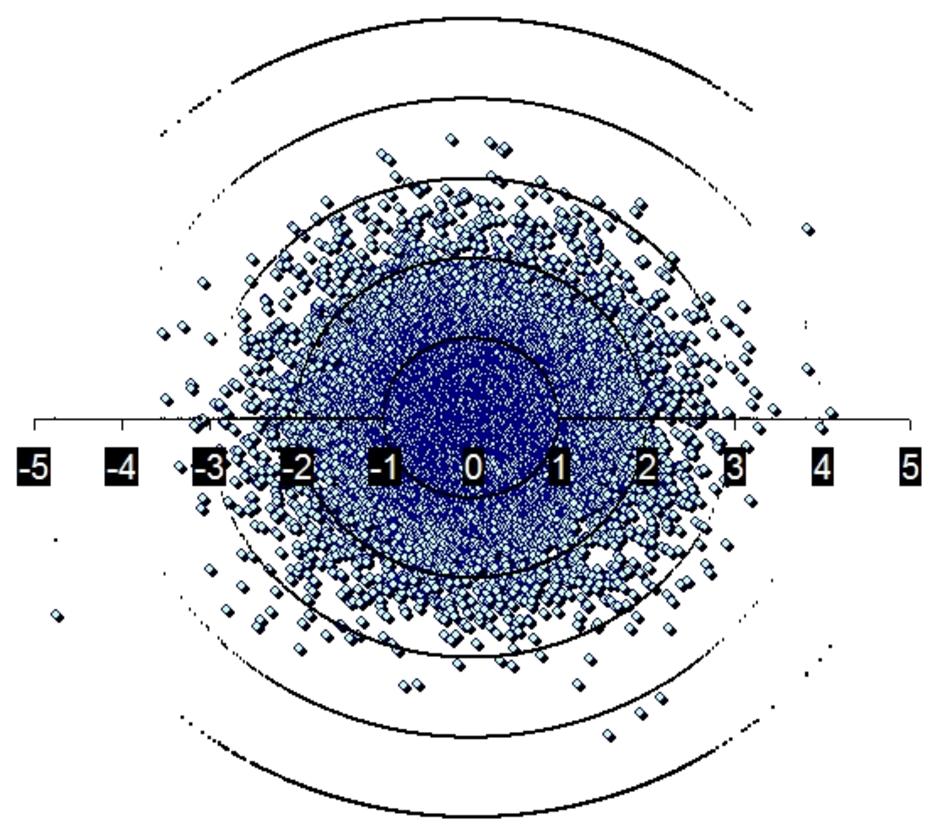
มีโอกาสที่จุดข้อมูล จะอยู่ในกรอบ -1 ถึง +1 เท่ากับ 68.26895%
มีโอกาสที่จุดข้อมูล จะอยู่ในกรอบ -2 ถึง +2 เท่ากับ 95.44997%
มีโอกาสที่จุดข้อมูล จะอยู่ในกรอบ -3 ถึง +3 เท่ากับ 99.73002%
มีโอกาสที่จุดข้อมูล จะอยู่ในกรอบ -4 ถึง +4 เท่ากับ 99.99367%
มีโอกาสที่จุดข้อมูล จะอยู่ในกรอบ -5 ถึง +5 เท่ากับ 99.99994%
คราวนี้ลองดูข้อมูลดิบตั้งต้น ของข้อมูลสองหย่อม
ข้อมูลแสดงไว้ในที่นี้ แสดงผลเป็นภาพสองมิติ เพื่อให้ดูเข้าใจง่าย เพราะสมองของคนเรา ไม่ชินที่จะมองมิติเดียว เวลามอง สิ่งที่ควรสนใจคือ ระยะห่างจากจุดศูนย์กลางเพียงอย่างเดียว โดยผมสุ่มหมุนทิศไปเรื่อย ๆ ทำให้เห็นภาพชัดเจนขึ้น

เวลาดูข้อสรุปทางสถิติว่า ค่าเฉลี่ยต่างกันไหม เขาไม่ได้ดูข้อมูลดิบ แต่ดูค่าเฉลี่ยที่สุ่มได้มา
เวลาเราไปเก็บข้อมูลมาหนึ่งครั้ง ก็ได้ค่าเฉลี่ยมาค่าหนึ่ง
เก็บเป็นร้อยครั้ง ก็ได้ค่าเฉลี่ยเป็นร้อยค่า
ถ้าเปรียบเทียบค่าเฉลี่ย ก็ต้องเอาค่าเฉลี่ยที่ได้ (ซึ่งจะเป็นศูนย์กลางของหย่อมข้อมูลดิบอีกทีนึง) มาลงจุด ซึ่งก็จะเห็นคล้ายภาพข้างบนเหมือนกัน
ดังนั้น ต่อจากนี้ไป จะพูดถึงแต่ค่าเฉลี่ยนะครับ ว่าเก็บข้อมูลครั้งนึง ได้หนึ่งจุด
พล็อตค่าเฉลี่ย เห็นกระจายทำนองนี้แหละ
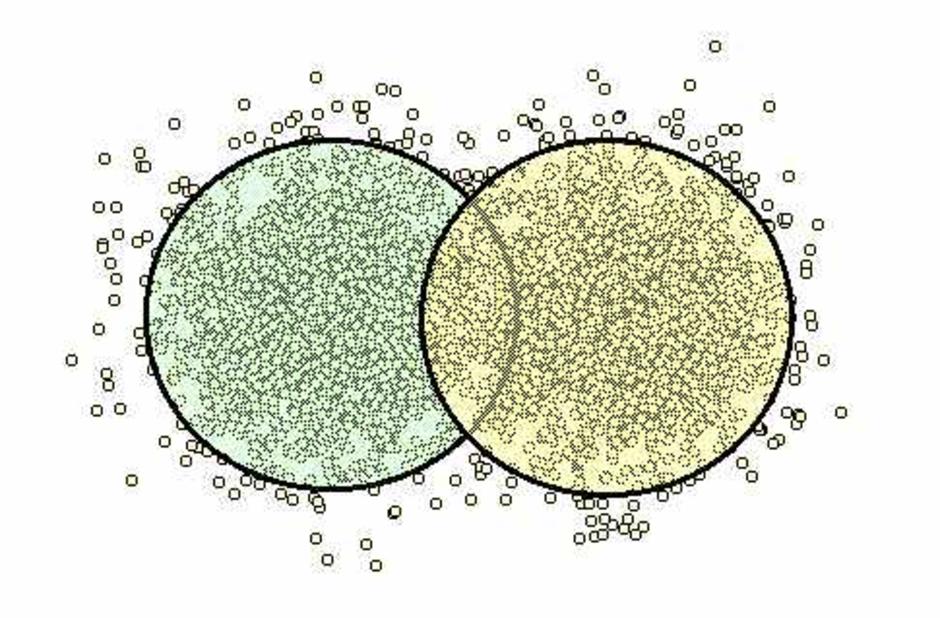
ถ้าเราเล็มขอบทิ้งไป alpha เหลือแกนกลางเป็น confidence interval เราก็จะเห็นส่วนที่เป็นแกนกลางที่ขอบคมกริบขึ้น เห็นข้อมูลสองหย่อมชัดเจน เพราะขีดตีวงไว้
สมมติว่า แต่ละหย่อม เล็มทิ้งไป 5 % (alpha level = 0.05) ทำให้แกนกลาง เหลือ 95 % ในกรณีนี้ เราจะเห็นว่า ข้อมูลสองหย่อมนี้ เกยกันอยู่
สถิติ มีศัพท์เรียกว่า "ไม่แตกต่างทางสถิติ ที่ alpha level = 0.05"
แต่เมื่อขยายค่า alpha ออกไปให้ใหญ่ขึ้น confidence interval แต่ละหย่อม ก็ค่อย ๆ หดตัวเล็กลง จนถึงจุดหนึ่ง ที่ขอบนอกของ confidence interval แตะกันพอดี
สมมติว่ากรณีนี้ เกิดการแตะกันพอดีที่ alpha = 0.07
ก็เรียกว่า p-value เป็น 0.07

ลองดูภาพ animation อีกแบบก็ได้




เราจะเห็นว่า เล็มไปที่ระดับ alpha = 0.17 จะทำให้ขอบในเริ่มขาดกัน ก็คือ p-value เป็น 0.17
ค่า alpha level ที่กรณีเฉพาะนี้ เรียกว่า p-value
อย่างไรก็ตาม ในทางปฎิบัติ เราไม่ได้เปรียบเทียบประชากรต่อประชากร แต่เปรียบเทียบ ค่าเฉลี่ย ต่อ ค่าเฉลี่ย
ดังนั้น สิ่งที่เราเห็นเป็นความฟุ้งรอบศูนย์กลาง จึงไม่ใช่ความฟุ้งของประชากร แต่เป็นความฟุ้งรอบค่าเฉลี่ย ซึ่งอธิบายโดย standard error of the mean ไม่ใช่ standard deviation (อ่านเรื่อง SE และ SD ในตอนถัด ๆ ไป)
ถ้าเราตั้งเป้าว่า เราจะเปรียบเทียบโดยใช้เกณฑ์ alpha เป็น 0.2
กรณีนี้ ก็จะสรุปว่า "แตกต่างกันทางสถิติอย่างมีนัยสำคัญ เพราะ p-value < alpha level"
แต่ถ้าเราตั้งเป้าว่า เราจะเปรียบเทียบโดยใช้เกณฑ์ alpha เป็น 0.05
กรณีนี้ ก็จะสรุปว่า "ไม่แตกต่างกันทางสถิติ เพราะ p-value > alpha level"
ถ้าดูให้ดี จะเห็นว่า ข้อมูลทั้งสองกอง ก็อยู่อย่างนั้นมาตลอด ไม่ได้เปลี่ยนแปลงอะไรเลย ที่เปลี่ยน คือ เกณฑ์ ว่าขนาดไหน ที่จะเรียกว่าต่าง (เกณฑ์ที่ว่า ก็คือ alpha level) แล้วก็ทำให้เราเห็นว่า ข้อมูลสองหย่อมนั้น ขาดออกมาจากกันไหม ถ้ามองว่าไม่ขาด ก็ไม่ต่างทางสถิติ ถ้ามองว่าขาด ก็จะต่างทางสถิติ
ดังนั้น การต่างหรือไม่ต่างทางสถิติ จึงเป็นสิ่งที่ต้องมีกรอบอ้างอิงเสมอ กรอบอ้างอิงนี้ ก็คือ alpha level หรือ confidence interval
ถ้าเห็น confidence interval ของข้อมูลสองกองเกยกันอยู่ เราก็บอกว่า สองกองนั้น ไม่ต่างกัน ที่ alpha นั้น ๆ
ถ้าเห็น confidence interval ของข้อมูลสองกอง แยกขาดออกจากกันได้ เราก็บอกว่า สองกองนั้น ต่างกัน ที่ alpha นั้น ๆ
ลองดูกรณีสมมติ ...ดูดาวคู่

กรณีแรก (ซ้ายสุด) ดูตอนฟ้ามัว เห็นแสงเป็นฝ้าเบลอ ๆ จนดูแล้วแยกไม่ค่อยออก เห็นราวเป็นดาวเดี่ยว กรณีนี้ ถ้าเปรียบเทียบระยะห่างระหว่างจุดศูนย์กลาง จะมี p-value สูง ทำให้ต้องสรุปว่า ไม่แตกต่างกันทางสถิติ (คนที่เรียนสถิติมาก็จะบอกว่า อ๋อ ก็ p-value สูงกว่า alpha นั่นไง มันจึงไม่แตกต่าง ก็คือภาพแรกนี้)
แต่พอท้องฟ้าเริ่มใสขึ้น ๆ สองหย่อมก็เริ่มสามารถมองเห็นขาดจากกันได้ชัดเจนขึ้นเรื่อย ๆ เกิดกรณีที่ แตกต่างกันอย่างมีนัยสำคัญ
แต่ประเด็นที่ต้องระลึกถึงคือ ระยะห่างทางกายภาพของดาวทั้งคู่ เหมือนเดิมทุกครั้ง แต่ก็อาจได้ข้อสรุปทางสถิติที่หลากหลาย ขึ้นกับคุณภาพข้อมูล ซึ่งในที่นี้ ก็คือ ความแปรปรวน หรือเทียบได้กับการที่ฟ้ามัวสลัวหม่น
พูดอีกนัยหนึ่ง แตกต่างทางสถิติ อาจไม่ได้บอกอะไรเลยว่า แตกต่างทางกายภาพไหม !
พวกงานวิจัยมั่วนิ่มจำนวนมาก ชอบเอาช่องโหว่ตรงนี้แหละมาใช้ เช่น บอกว่า ยานี้ลดความดันดีกว่ากลุ่มยาหลอกได้ดีอย่างมีนัยสำคัญยิ่งทางสถิติ แต่อ้อมแอ้มเลี่ยงไปว่า ที่ต่างน่ะ แค่ 10 mmHg ซึ่งจิ๊บจ๊อยมาก ซึ่งงานวิจัยที่ดี ควรแตกต่างทั้งทางสถิติ และแตกต่างทางปฎิบัติในชีวิตจริง จึงจะถือว่า แตกต่างอย่างมีคุณภาพ
สนใจอ่าน เรียนสถิติด้วยภาพ แบบครบทุกตอน เข้าไปที่
http://www.gotoknow.org/posts?tag=เรียนสถิติด้วยภาพ<p></p>
เริ่มเห็นภาพครับ
ข้อมูลมันก็อยู่ของมันอย่างนั้น แต่เราไปนิยามมันว่าต้องกำหนดค่า alpha เท่าไร
ความแตกต่างจึงเกิดจาก การกำหนดค่า confidence interval
ขอบคุณครับ อ.
เริ่มเข้าใจมากขึ้นคะ
ขอบคุณคะ
เพิ่งถึงบาง..อ้อ
ขอยืนยันการติดตามอ่านต่อครับ
ขอบคุณครับ
หนูอ่านมาหลายหัวข้อแล้วค่ะ ชอบทุกหัวข้อเรย เข้าจัยง่ายดี
หนูคงจะสอบnational boardหัวข้อผ่านเพราะอาจานแน่ๆๆ
ขอบคุนมากค่ะ
เยี่ยม ครับ
ลมหวน
ขอบคุณมากค่ะ
อธิบายเข้าใจง่ายดีมากครับ
แต่ผมยังตามไม่ทันที่ภาพสุดท้าย เรื่อง Null hyprothesis
ไม่ทราบว่า การจะให้คำว่า Reject หรือ Accept ขึ้นอยู่กับ คำถาม No statistical difference , Significant , ... หรือไม่ครับ ?
ยังงงคำถามครับ
ไม่เข้าใน คำศัพท์ภาษาอังกฤษในย่อหน้าสุดท้ายนะครับ
อ๋อ ต้องไปอ่านต่อใน http://gotoknow.org/blog/offshoot/223229 ครับ
เป็นเว็บที่ดีมากจริงๆ
สุดยอดเลยค่ะอาจารย์ ถึงบางอ้อ
รูปภาพหายไป ขอช่วยลงใหม่ให้ได้ไหมครับกราบบบ