จากประสบการณ์ ตอนเริ่มทำวิจัย หลังจากใช้โปรแกรมคำนวณค่าทางสถิติแล้ว ขั้นตอนอันน่าเบื่อ และน่าเวียนหัวคือการนำมาใส่ในตาราง..ยังจำได้ว่า พิมพ์ log file 30 กว่าหน้า ใช้เวลาครึ่งวันในการนำตัวเลขมาใส่..ปัดทศนิยม เช็คอีก..อ้าวมีผิด..วนไปวนมา..สรุปครึ่งวันที่เหลือก็สลบคะ..
หลังจากเจ็บใจอยู่นาน ก็ได้พบเทคนิคดีๆ ที่เขียนในหนังสือของ J. Scott long ที่ช่วยให้การทำตารางสรุปสถิติง่ายขึ้น..จึงอยากนำมาแบ่งปันสำหรับมือใหม่คะ สำหรับมือโปรอาจรู้อยู่แล้ว..
หมายเหตุ..
- ภาษา Stata อาจดูน่ากลัว แต่ไม่ต้องตกใจคะ เหมือนกับรถยนต์
เราไม่ต้องรู้การทำงานของเครื่องยนต์ทั้งหมด แค่รู้ว่าขับอย่างไรก็พอ
เช่นเดียวกัน
เราแค่รู้ว่าส่วนไหนเราจะแทนค่าที่เราต้องการเข้าไปก็พอแล้ว
- ข้อมูลตัวเลขต่างๆ เป็นค่าสมมติ อย่านำไปอ้างอิงนะคะ..
กรณี continuous variable
ถ้าเราอยากรู้ว่า mean ของ continuous variable ระหว่างกลุ่ม
control กับ treatment ต่างกันหรือไม่ ก็จะใช้ ttest..ปัญหาคือ ถ้ามี
variable อยู่ 10 ตัว มานั่งพิมพ์คำสั่งทีละอันๆ
นั้นแสนจะเสียเวลา
ดีขึ้นมาหน่อย ก็ใช้ loop ดังตัวอย่าง..
และ แดง คือ variable ของเราเอง
สังเกตว่าบรรทัดสุดท้ายนั้น ก็คือ ttest ที่แบ่งเป็นสองกลุ่ม ธรรมดานี่เอง
ส่วนที่เป็นสีดำนั้น ต้องใส่ตามนี้ทุกระเบียบนิ้วคะ ทั้งตำแหน่งเครื่องหมายปีกกา จุดเล็กจุดน้อย..Stata เป็นโปรแกรมที่เก่งแต่จู้จี้คะ
ซึ่งก็จะได้ตารางแบบฉบับ ttest มาแต่ละ variable ทำให้ต้องพิมพ์ log file หลายหน้า แล้วมาตาลายเลือกค่าลงตารางอยู่ดี
ใจจริงเราอยากให้ Stata แสดงผลสรุปออกมาแบบนี้เลยต่างหาก
วิธีแรกคือ พิมพ์ .help ttest แล้วหาดูตรง scalars หรือลองทำ ttest สักค่านึง แล้วใช้คำสั่ง . return list ยกตัวอย่าง
.ttest age, by bdzbi_get)
คะ เราก็รู้ได้ว่าอะไรคืออะไร
หากวิธีนี้ดูยุ่งยากไปนิด สามารถใช้ชุดคำสั่งเขียน ที่ต้องติดตั้งเพิ่มเติม (ฟรี) ชื่อ tabout โปรดติดตามต่อไปคะ
กรณี Dichotomous variable
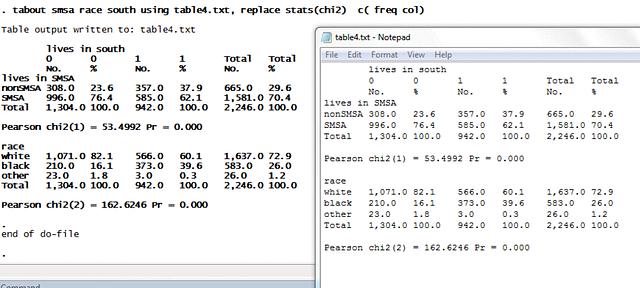
ตารางแสดง proportion และ chisquare วิธีง่ายที่สุดคือการใช้ tabout
.findit tabout
ตัวอย่าง
. tabout smsa race south using table4.txt, replace c( freq col) stats(chi2)
variable ที่เราต้องการแบ่งกลุ่ม
ไฟล์ txt ที่ต้องการให้ผลตารางไปปรากฎ ซึ่งสะดวกต่อการพิมพ์ได้ทันที
option ในการแสดงผล ในที่นี้คือ ให้แสดง content ได้แก่ frequency และแสดง % ตามคอร์ลัมน์ --ดังนั้นกรณี continous variable เราสามารถเลือก mean, median, sd ได้เช่นกัน ส่วน statistical test เลือก chi square


ขอบคุณคะ (แต่มีเรื่องอยากสอบถามนอกประเด็นนิดนึงคะ อยากทราบว่าตัวแปรที่แปลงมาจากตัวแปรอีกตัวแปรหนึ่ง เช่น มีตัวแปร x z แล้วตัวแปร aa สร้างมาจาก x/z คะ เมื่อเราต้องการหา correlation coefficeint ต้องนำตัวแปรใหม่คือ aa มาหาด้วยหรือไม่คะ เพราะถ้านำมาหาด้วยจะมีความสัมพันธ์กันสูงมากคะ แล้วการใช้คำสั่ง corr กับ pwcorr ต่างกันอย่างไรคะ ขอบคุณค่า)
ขอโทษคะคุณ nan ที่เข้ามาตอบช้าไปนิด
คำถามน่าสนใจคะ คิดว่าควรใส่ทั้ง x, z และ x/z ใน model คะ
ลองคิดเป็นตัวอย่างในชีวิตจริงทางการแพทย์ เช่น
x = BUN -> สะท้อนการคั่งของสาร urea ในร่างกาย
y = Creatinine -> สะท้อนอัตราการขับถ่ายของแสียของไต
aa = BUN/Cr -> สะท้อนภาวะเลือดมาเลี้ยงไตน้อย เช่น dehydration
กรณีนี้ ใน model ก็จะใส่ท้ง BUN , Cr และ BUN/Cr คะ
สำหรับ corr และ pwcorr โดยส่วนตัวไม่ค่อยได้ใช้ function นี้คะ แต่ลองอ่านจาก http://statalist.1588530.n2.nabble.com/st-Pearson-correlate-returned-values-corr-vs-pwcorr-td1644033.html
เข้าใจว่า pwcorr = pair wise correlation จึงต่างจาก corr เฉยๆ ตรงที่ แสดง p value ของแต่ละคู่ได้ด้วยการใส่ option "sig"
ทดลองดูได้คะ ว่าต่างกันอย่างไร
sysuse auto, clear
corr headroom turn mpg
pwcorr headroom turn mpg, sig
เรียนอาจารย์ครับ ถ้านักเรียนท่านใดต้องการหนังสือภาษาไทยของ STATA ขออนุญาตินำเสนอหนังสือทางสถิติภาษาไทย "การวิเคราะห์ข้อมูลด้วยโปรแกรม STATA 10" ครับ, จัดพิมพ์โดยสำนักพิมพ์จุฬาลงกรณ์มหาวิทยาลัยครับ (เทคนิคที่อาจารย์กล่าวถึงในหน้านี้ผมก็พึ่งได้ไปเรียนมาจากที่ LSHTM เหมือนกันครับ หลังจากใช้งานมานานหลายปี)
เรียนคุณหมอ ดิเรก มธุรสกุล ขอบคุณมากคะที่ให้เกียรติ comment และแนะนำหนังสือภาษาไทย น่าหามาอ่านกันคะ..แต่น่าน้อยใจอยู่หน่อยว่า..พอเรียน STATA มา แล้วคนอื่นๆ รอบตัวใช้ SPSS กันหมด
@คุณ CMUpal ครับ ผมว่าไม่เป็นไรหรอกครับ ถ้าคนใช้ SPSS เป็นเขาเข้าใจสถิติถูกต้องดีครับ เพราะลึกๆ แล้วผมก็รู้สึกว่า STATA ก็เป็นแค่เครื่องมือเหมือนกันครับ (แต่ STATA มันก็ดีกว่า SPSS หลายๆ อย่างจริงๆ อยู่ดี) ... อ้อ อีกอย่างนึงครับ ระดับโลกเขาก็ใช้ STATA กันเยอะนะครับ อย่าคิดมากเลยครับ ไม่ต้องเหมือนคนส่วนใหญ่ในประเทศก็ได้ครับ เพราะบ้านเรา Microsoft ครองตลาดครับ .. คิดเหมือนว่า STATA เป็นแอปเปิ้ลก็ได้ครับ
ขอบคุณคะ อ.หมอดิเรก
ขออนุญาต แปะลิงค์ หากผู้ใดสนใจตำรา STATA ภาษาไทย แต่งโดย นพ.ดิเรก ลิ้มมธุรสสกุล คะ :-)
http://www.chulabook.com/description.asp?barcode=9789740328346
ตอนนี้เห็น ที่ตัวเองเขียนไว้ ก็จะเป็นลม (ด้วยคน) คะ :-)
วันนี้ไปนั่งเรียน STATA วินมากเลยคะ
กลับบ้าน ลองค้นดูเพื่อทบทวน(เพราะไม่รู้เรื่อง) เลยมาพบบันทึกของคุณหมอ
ยากนะคะสำหรับคนบ้านๆ อย่างพี่กระติก
เอาใจช่วยค่ะ พี่กระติก :)
ผมอยากทราบวิธีวิเคราะห์ค่าความเชื่อมั่นด้วย Stata ครับ..