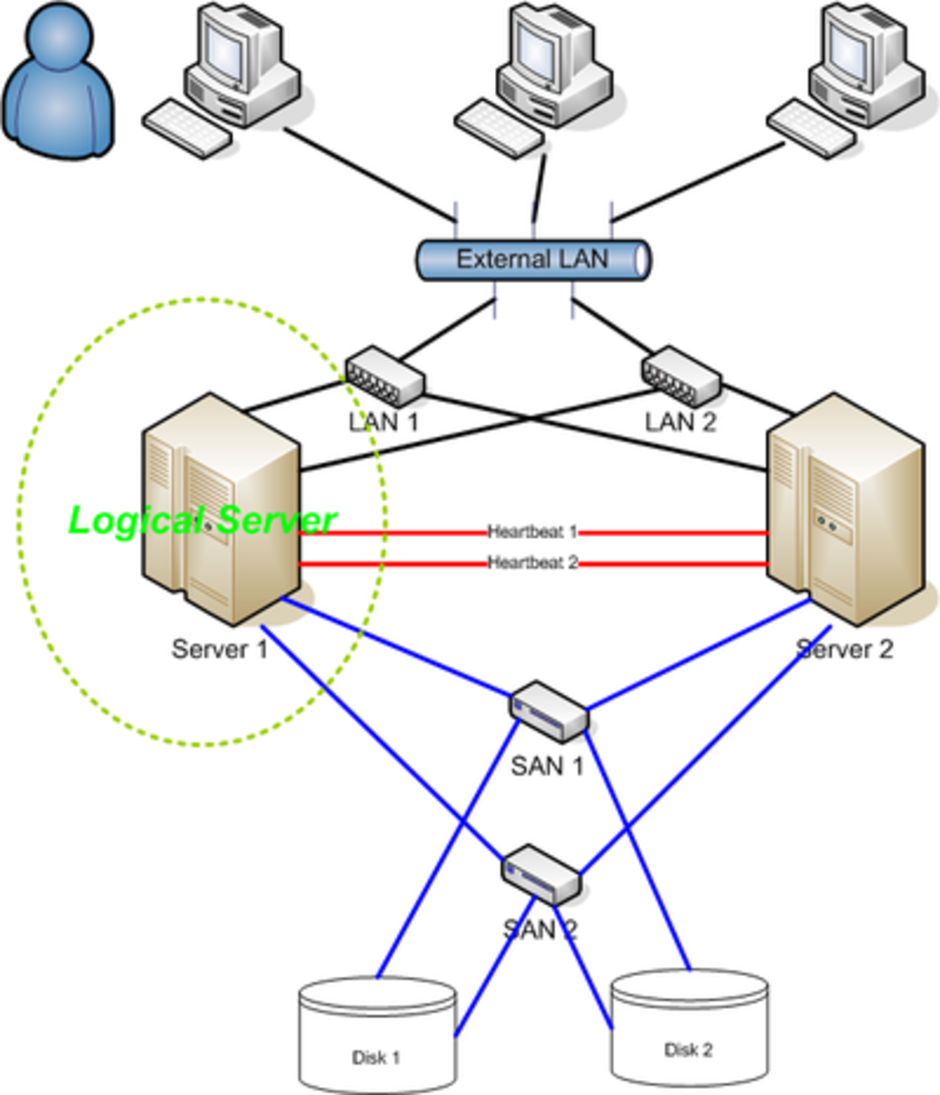
High-availability cluster
High-availability clusters (also known as HA Clusters or Failover Clusters) are computer clusters that are implemented primarily for the purpose of providing high availability of services which the cluster provides. They operate by having redundant computers or nodes which are then used to provide service when system components fail. Normally, if a server with a particular application crashes, the application will be unavailable until someone fixes the crashed server. HA clustering remedies this situation by detecting hardware/software faults, and immediately restarting the application on another system without requiring administrative intervention, a process known as Failover. As part of this process, clustering software may configure the node before starting the application on it. For example, appropriate filesystems may need to be imported and mounted, network hardware may have to be configured, and some supporting applications may need to be running as well.
HA clusters are often used for critical databases, file sharing on a network, business applications, and customer services such as electronic commerce websites.
HA cluster implementations attempt to build redundancy into a cluster to eliminate single points of failure, including multiple network connections and data storage which is multiply connected via Storage area networks.
HA clusters usually use a heartbeat private network connection which is used to monitor the health and status of each node in the cluster. One subtle, but serious condition every clustering software must be able to handle is split-brain. Split-brain occurs when all of the private links go down simultaneously, but the cluster nodes are still running. If that happens, each node in the cluster may mistakenly decide that every other node has gone down and attempt to start services that other nodes are still running. Having duplicate instances of services may cause data corruption on the shared storage.
================================================
Application Design Requirements
Not every application can run in a high-availability cluster environment, and the necessary design decisions need to be made early in the software design phase. In order to run in a high-availability cluster environment, an application must satisfy at least the following technical requirements:
-
There must be a relatively easy way to start, stop, force-stop, and check the status of the application. In practical terms, this means the application must have a command line interface or scripts to control the application, including support for multiple instances of the application.
-
The application must be able to use shared storage (NAS/SAN).
-
Most importantly, the application must store as much of its state on non-volatile shared storage as possible. Equally important is the ability to restart on another node at the last state before failure using the saved state from the shared storage.
-
Application must not corrupt data if it crashes or restarts from the saved state.
The last two criteria are critical to reliable functionality in a cluster, and are the most difficult to satisfy fully. Finally, licensing compliance must be observed.
===========================================
Node Reliability
HA clusters usually utilize all available techniques to make the individual systems and shared infrastructure as reliable as possible. These include:
-
Disk mirroring so that failure of internal disks does not result in system crashes
-
Redundant network connections so that single cable, switch, or network interface failures do not result in network outages
-
Redundant Storage area network or SAN data connections so that single cable, switch, or interface failures do not lead to loss of connectivity to the storage (this would violate the share-nothing architecture)
-
Redundant electrical power inputs on different circuits, usually both or all protected by Uninterruptible power supply units, and redundant power supply units, so that single power feed, cable, UPS, or power supply failures do not lead to loss of power to the system.
These features help minimize the chances that the clustering failover between systems will be required. In such a failover, the service provided is unavailable for at least a little while, so measures to avoid failover are preferred.
===============================================
HA (High Avail.) Cluster Products
Common Cluster
These products are found extensively in commercial or research/academic use:
-
Veritas Cluster Server - multi-platform
-
Sun Cluster - Solaris/OpenSolaris only
-
Netra High Availability Suite - Solaris and Linux
-
OpenVMS - The original clustering OS - runs on VAX, Alpha and Itanium(2) only, still no EOL
-
HP ServiceGuard for HP/UX and Linux
-
Linux-HA — a commonly used free software HA package for the Linux OS.
-
Red Hat Cluster Suite - Linux only
-
IBM High Availability Cluster Multiprocessing (HACMP) for AIX and Linux
-
Microsoft Cluster Server (MSCS) - Windows only
-
Parallel Sysplex - unique to IBM mainframes
-
IBM Tivoli System Automation - z/OS, AIX, Linux, Windows Server 2003
Other Clusters
These cluster systems are less commonly found in production.
-
NEC ExpressCluster - Windows and Linux
-
-
-
Novell Cluster Services for NetWare and Linux
-
PRIMECLUSTER for Solaris and Linux
-
OpenClovis ASP Open Source Solution
-
openMOSIX Gentoo Linux
-
ENEA Element for Super Cluster Architectures
-
GoAhead SAFfire & SelfReliant for Linux, Windows, VxWorks and Solaris
-
SteelEye LifeKeeper for Linux and Windows
-
RSF-1 for AIX, HP-UX, Linux, Solaris, Mac OS X
-
HA/FST - Open Source HA for Solaris (SPARC,x86)
-
HA-OSCAR - High Availability Open Source Cluster Application
-
OpenSSI for Linux
-
EMC Corporation AutoStart for all platforms [1]
-
VMware Infrastructure 3 (VI3) - High Availability for Virtual Servers
-
NCache - Clustered object caching and Distributed ASP .NET Session State solution
-
WanSyncHA - High Availability for MS platforms, based on real-time replication and automatic failover and failback
-
MyWindowsHearbeat - Open Source Solution for Windows (IP - Failover,..)