เวลาดูค่าเฉลี่ยของตัวเลขในรายงานการวิจัย บ่อยครั้ง ที่เขารายงานค่าเฉลี่ย และตามด้วย standard deviation หรือ standard error of the mean อย่างใดอย่างหนึ่ง
คำถามคือ ทำไมต้องทำให้มันยุ่งยากอย่างนั้น ? ชีวิตยังลำบากไม่พอรึไงฮึ ?
ก็ต้องย้อนกลับมาดูตั้งแต่รากเหง้า ว่า standard deviation เกิดขึ้นมา เพื่อบอกว่า ข้อมูล "เละ" แค่ไหน
ข้อมูลเละ(กระเจิง)มาก ค่า SD หรือ standard deviation ก็จะมาก ถ้าข้อมูลดี ข้อมูลนิ่ง ค่า SD ก็จะน้อย
Standard deviation จะบอกว่า ประชากรทั้งหมด เป็นอย่างไร มีความแตกต่างหลากหลายไหม
ตอนก่อนหน้า แนะนำให้รู้จัก confidence interval ไปแล้ว ว่าเหมือนเงาะกล้อนเปลือก

SD ก็มีความหมายเป็นหน่วยมาตรฐานของการวัด confidence interval อีกที
ดังนั้น หาก confidence interval กว้าง ค่า SD ก็จะมาก
หาก confidence interval แคบ ค่า SD ก็จะน้อย
ที่บอกว่าเป็นมาตรฐานก็คือ เราไม่ต้องทราบรายละเอียดข้อมูลมาก่อน แต่เราพอจะบอกคร่าว ๆ ทำนายอะไรบางอย่างได้ล่วงหน้า เช่น ข้อมูลดิบ 19 ในทุก 20 รายการ จะอยู่ห่างจากค่าเฉลี่ยในช่วงไม่เกิน 2 เท่าของ SD
ข้อมูลดิบ 19 ในทุก 20 รายการ ก็คือช่วงความเชื่อมั่น 95 % นั่นเอง (95% = 19/20)
เช่น ถ้าบอกว่า ประชากรของประเทศ XXX (ไม่ได้หมกมุ่นนะนี่ ^ ^) มีความสูง 160 ซม. และมีค่า SD 10 ซม. นี่ เราก็จะบอกคร่าว ๆ ว่า ประชากรส่วนใหญ่ อยู่ในช่วง 160 ซม. บวก หรือ ลบ ด้วย [10 ซม. คูณ ค่าคงที่ที่สอดคล้องกับคำว่า "ส่วนใหญ่"]
เช่น
ถ้านิยามว่า คนส่วนใหญ่ หมายถึง 68.27 % ค่าคงที่นี้ จะมีค่าเท่ากับ 1
ถ้านิยามว่า คนส่วนใหญ่ หมายถึง 95.45 % ค่าคงที่นี้ จะมีค่าเท่ากับ 2
ถ้านิยามว่า คนส่วนใหญ่ หมายถึง 99.73 % ค่าคงที่นี้ จะมีค่าเท่ากับ 3
ถ้านิยามว่า คนส่วนใหญ่ หมายถึง 99.9999998 % ค่าคงที่นี้ จะมีค่าเท่ากับ 6
เวลาเราบอกว่า ประชากรทั้งหมด ในที่นี้ เรากำลังหมายถึงคนทั้งชาติในประเทศ XXX
นั่นคือ SD บอกถึงความหลากหลายของประชากร
ถามว่า ต้องไปตามดูประชากรทุกคนทั้งประเทศไหม จึงจะทราบ SD ?
โชคดีที่ว่า ไม่จำเป็น
ถ้าเก็บข้อมูลอย่างสุ่มที่กระจายไปทั่ว ๆ เก็บมาไม่มากนัก ก็รู้แล้ว
เก็บมา 10 คนก็พอทราบคร่าว ๆ เพียงแต่เสียที่ทำซ้ำแล้วอาจไม่ได้ผลเหมือนเดิม
เก็บมา 1000 คน ก็ยังคล้ายเดิม แต่ตัวเลขนิ่งขึ้น
ดังนั้น ค่า SD จึงเป็นค่ากลางที่ไม่ควรขึ้นกับขนาดของการสุ่มเลย คือสุ่มมากมากหรือน้อย ค่า SD ยังไง ๆ ก็ต้องได้ใกล้ค่า SD ของประชากรเสมอ เพราะความหลากหลายของประชากร ไม่ขึ้นกับการที่เราไปเห็นมาแล้วทั้งหมด หรือได้เห็นแค่บางส่วน
แล้ว SE ล่ะ ?
SE หรือ standard error of the mean จะไม่ได้สนใจที่การกระเจิงของประชากรอีกต่อไป
SE เป็นตัวบอกว่า ถ้าคุณสุ่มประชากรมาวัด ค่าเฉลี่ยของคุณ จะนิ่งไหม ?
SE เป็นตัวบอกถึงคุณภาพของการสุ่ม
SE จะบอกว่า การสุ่มของเรา "ได้เรื่อง" ไหม
เช่น ถ้าเก็บมา 10 คน แม้ทราบคร่าว ๆ ว่าค่าเฉลี่ยเป็นเท่าไหร่ แต่ทำซ้ำแล้วอาจไม่ได้ผลเหมือนเดิม ไม่เหมือนถ้าสุ่มมาทีละล้านคน ซึ่งทำซ้ำกี่ที ๆ ก็ได้ค่าประมาณเดิมเสมอแบบ"ไม่กระดิก"ต่างกันเลย
ถ้าเอาค่าเฉลี่ยจากการสุ่มแต่ละครั้งที่ไม่ค่อยนิ่งเท่าไหร่ มาหาค่า SD
ค่าที่ได้ ก็จะเป็น SD ของค่าเฉลี่ย
เป็น SD ของผลจากการสุ่มมาวัดครั้งละหลาย ๆ หน่วย หลาย ๆ คน
ไม่ใช่ SD ของประชากรรายคนอีกต่อไป
เพื่อไม่ให้เกิดความสับสน SD ของค่าเฉลี่ย จึงเรียกว่า standard error of the mean แทน ซึ่งรู้จักกันในชื่อ SE
SE เป็นการบอก ความกระเจิง ("standard error") ของค่าเฉลี่ย ("of the mean") ที่เป็นผลจากการสุ่มมาวัด ขนาดการสุ่มจึงมีผลกระทบอย่างรุนแรงต่อค่านี้
SE ก็คือ SD ของค่าเฉลี่ยที่ได้จากการสุ่มเมื่อทำซ้ำ
ถ้าเรา สุ่ม N คน มาวัดเพื่อหาค่าเฉลี่ย เราก็ได้ค่าเฉลี่ยมาค่าหนึ่ง
ถ้าเราทำซ้ำ คือ สุ่ม N คน มาวัดเพื่อหาค่าเฉลี่ย เราก็ได้ค่าเฉลี่ยมาอีกค่าหนึ่ง
ทำซ้ำหลาย ๆ ครั้ง ทำซ้ำไปเรื่อย ๆ เราก็จะได้ค่าเฉลี่ยจำนวนหลายรายการ
เราจะพบว่า ค่าเฉลี่ยเหล่านี้เมื่อสุ่มทดลองวัดซ้ำ มี "ความเละ" ที่เปลี่ยนไปตามขนาดของการสุ่ม N
ถ้า N น้อย "ความเละ" ของเหล่าค่าเฉลี่ยที่ได้ จะสูง
ถ้า N มาก "ความเละ" ของเหล่าค่าเฉลี่ยที่ได้ จะต่ำ
ถ้าเมื่อไหร่ วัดทุกคนในประเทศโดยไม่ซ้ำและไม่สุ่ม ความเละที่ว่า จะหมดไป กลายเป็นศูนย์
ดังนั้น ค่า SE ซึ่งบอก "ความเละ" ของเหล่าค่าเฉลี่ยที่ได้ จะไม่เหมือนกับ SD
SD บอกลักษณะของประชากรทั้งหมดโดยรวม โดยไม่เกี่ยวเลยว่า เราจะไปสุ่มมามาก หรือสุ่มมาน้อย
Standard error of the mean (SE) บอกถึงความนิ่งของผลการวัดของเรา
SE จะเท่ากับ SD ของประชากร เมื่อเราสุ่มวัดได้เพียงครั้งละคนเดียว
แต่ SE จะน้อยลงเรื่อย ๆ เมื่อเราสามารถเพิ่มขนาดของกลุ่มประชากรที่ไปสุ่มมาวัดได้
จาก wikipedia มีสูตรว่า 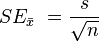 เมื่อ n คือขนาดของการสุ่มมาวัด และ s คือ SD
เมื่อ n คือขนาดของการสุ่มมาวัด และ s คือ SD
ถ้าสุ่มมาวัดครั้งละคน แล้วเอามาหาความสูงเฉลี่ย เราควรจะคาดว่า ค่าเฉลี่ยนี้ ไม่นิ่ง

ตัวเลขในแถวสุดท้ายที่ระบายสีเหลือง
เป็นค่าเฉลี่ยของตัวเลขด้านซ้ายที่อยู่ในบรรทัดเดียวกัน
กรณีที่วัดครั้งละคน การที่ค่าเฉลี่ยไม่นิ่ง ก็ไม่แปลก เพราะนี่ก็คือการเลือกประชากรมาดูทีละคน เดี๋ยวเจอคนสูง เดี๋ยวเจอคนเตี้ย มันก็ต้องหลากหลายอยู่แล้ว
ถ้าเอาค่าเฉลี่ยที่เกิดจากการสุ่ม 1 คนมาดูความหลากหลาย กรณีนี้ ก็จะเป็นการดูความหลากหลายของประชากรนั่นเอง
ดังนั้น ถ้าสุ่มมาวัดครั้งละคนเพื่อทำนายความสูงเฉลี่ยของประชากร ค่าเฉลี่ยที่ได้ จะกระเจิงมาก เหมือนการกระเจิงในตัวประชากร
ในกรณีที่สุ่มมาครั้งละคน จะเห็นว่า ค่าเฉลี่ย จะมีพฤติกรรมเหมือนกับข้อมูลดิบเปี๊ยบ กรณีนี้ SE = SD
กรณีที่ n=1 นี้ ค่า SE ได้ราว 10
แต่จะเกิดอะไรขึ้น ถ้าผมสุ่มคนมาวัดความสูงทีละ 4 คน ?
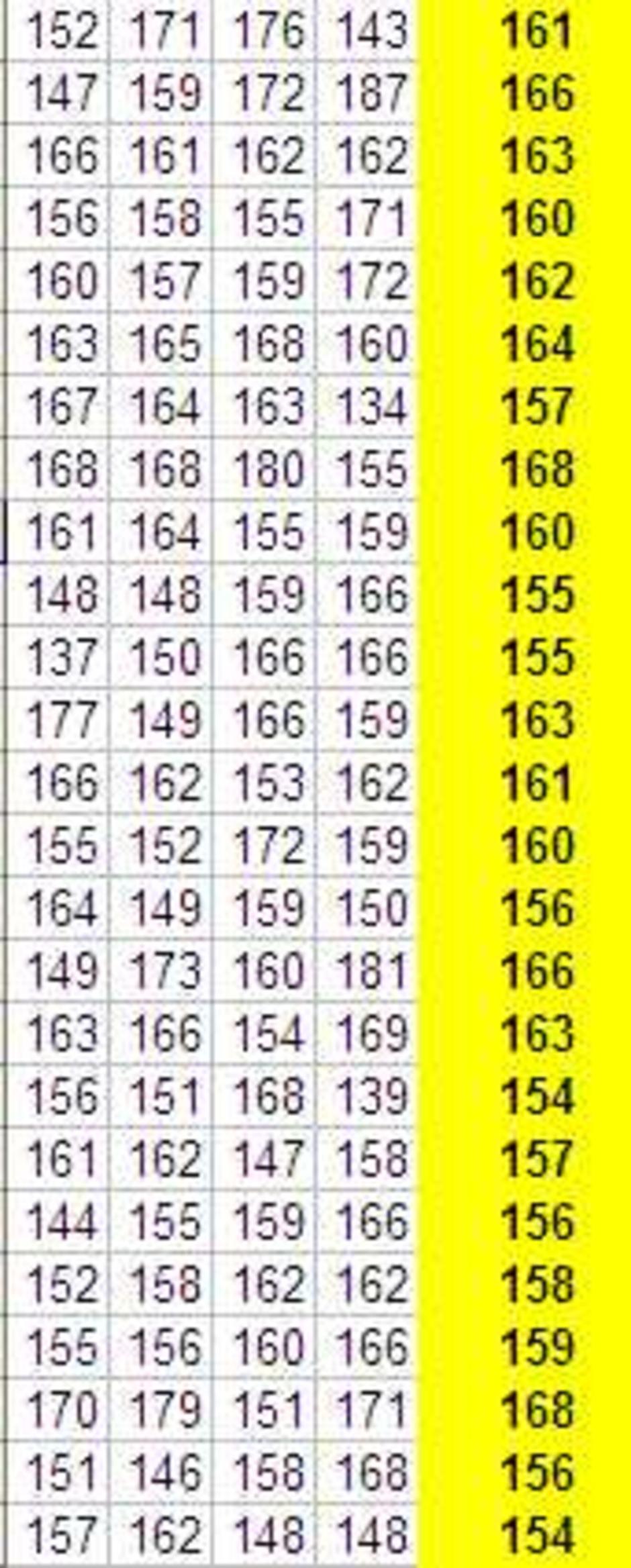
ถ้าดูค่าเฉลี่ยของทุก 4 คนที่สุ่มมา จะเห็นว่า
เฉลี่ยแล้วจะนิ่งขึ้นกว่าเดิมมากอย่างเห็นได้ชัด
ถ้าหา SD ของค่าเฉลี่ยที่ทำซ้ำๆ กัน (ก็คือค่า SE นั่นเอง) เราจะพบว่า SE มีค่าราวครึ่งเดียวของกรณีที่สุ่มมาครั้งละคน คือค่าที่ได้ของ SE จะได้ราว 5
ที่ค่าเฉลี่ยนิ่งขึ้น เพราะเราสุ่มมามีทั้งคนสูงและคนเตี้ย เวลามาเฉลี่ย ค่าความผิดปรกติทั้งสองฟากก็อาจมาหักล้างกันเองจนหายไปได้เป็นส่วนใหญ่ มีเพียงส่วนน้อยที่ยังมีปัญหากลุ่มมากผิดปรกติมาสุมหัวตั้งแก๊ง หรือกลุ่มน้อยผิดปรกติมาสุมหัวตั้งแก๊ง
คราวนี้ลองสุ่มครั้งละ 25 คนบ้าง

ข้อสรุปคล้ายเดิม เราจะเห็นว่า ค่าเฉลี่ย เกาะติดใกล้ 160 มาก และค่า
SE ก็ยิ่งน้อยลงไปอีก คือถ้าหา SD ของแถวสุดท้าย (ค่าเฉลี่ยรายบรรทัด)
จะมีค่าราว 2
ผมเอาข้อมูลตามที่แสดงไว้ในตารางที่ตัวเลขอัดแน่นมาทำเป็นกราฟ จะได้เห็นภาพชัดขึ้น

สูตรที่ว่า จึงใช้ได้ในกรณีนี้
อย่างคร่าว ๆ
สูตรนี้มีประโยชน์อย่างไร
ลองนึกถึงว่า ถ้าผมมีงบจำกัดมาก ไม่สามารถจะสุ่มคนทั้งประเทศ แต่มีงบสุ่มคนมาได้เพียง 25 คน ผมหาค่า mean และ SD จาก 25 คน ผมก็จะสามารถทำนายได้ว่า SE จะมีค่าเป็นเท่าไหร่ (ตามสูตรดังกล่าว)
รู้ SE ของค่าเฉลี่ย ผมคูณด้วยสอง ผมก็พูดได้ว่า ค่าเฉลี่ยความสูงของประชากรทั้งประเทศ ต้องอยู่ในช่วง mean บวกสองเท่าของ SE ถึงลบสองเท่าของ SE
เช่น สุ่มมาเพียง 25 คน หาค่าเฉลี่ยได้ 159.5 ซม และ SD 9.9 (แทนค่าในสูตร ได้ SE ประมาณ 2.0) ผมก็ฟันธงได้ว่า ค่าเฉลี่ยที่ผมได้ มีโอกาส 95% ที่จะอยู่ในช่วง 155.5 - 163.5 ซม (mean + 2 SE)
จะเห็นได้ว่า โดยภาพรวมแล้ว
standard deviation บอกว่า ประชากรหลากหลายเพียงใด
แต่ standard error of the mean จะเป็นตัวบอกว่า ค่าเฉลี่ยของเราที่ได้จากการสุ่มมานิดเดียว เชื่อได้แค่ไหน
สรุปแล้ว มีประโยชน์ทั้งคู่ อย่าไปตั้งข้อรังเกียจรังงอนมันเลยครับ
หน้าที่ของเราคือ รู้จักทั้งคู่ และต้องรู้ว่า เมื่อไหร่ใช้ตัวไหน
สนใจอ่าน เรียนสถิติด้วยภาพ แบบครบทุกตอน เข้าไปที่
http://www.gotoknow.org/posts?tag=เรียนสถิติด้วยภาพ
อนุญาต ให้หมดแรงได้เท่ากับ จำนวนวันหยุดสุดสัปดาห์(N น้อย) ค่าSD จะได้ไม่แกว่ง
สมัยเรียนที่จำนวนN ของอายุน้อย ๆ อ่านไม่รู้เรื่อง เท่าตอนนี้ N ของอายุมากกว่า มาก ๆ ....จึงยังอยากอ่านต่อค่ะ
ขอบคุณค่ะ
ดีใจจนอดไม่ได้....ที่จะมาขอบคุณอาจารย์ wwibul
เคยหาตัวอย่างคำพูดที่จะให้ลูกศิษย์เข้าใจในเรื่องสถิติ จนบางครั้งเคยยกตัวอย่าง การกระจาย โดยเปรียบเทียบกับกองขี้ควายที่โดนรถเหยียบกระจาย (ขอโทษที่ใช้คำไม่เหมาะ)
ผมเองพึ่งสมัครเป็นสมาชิก G2K ต้องขออนุญาต นำแนวทางนี้ไปให้ความกระจ่างแก่ลูกศิษย์ต่อด้วยนะครับ
ซินเจียยู่อี่ ซินนี้ฮวดไช้ ครับ
ที่อาจารย์อธิบายมา เป็นการสอนได้ดีเลยนะคะ
แต่ตอนนี้ นึกไปถึง สถิติ ในเรื่องความเป็นไปได้
เวลาฟังการพยากรณ์ของผู้เชี่ยวชาญในด้านต่างๆ โดยเฉพาะเรื่องหุ้น
จะยกสถิติอะไรมาก็ตาม ตัวตัดสินจริงๆ คือความรอบคอบมากขึ้นในการตัดสินใจจะลงทุนเงินออมก้อนสำคัญของชีวิต
อยากเรียนถามค่ะ ว่าถ้าเรามีค่า mean difference อยู่ แล้วใน paper ไม่ได้บอกค่า SD แต่บอกค่า 95% CI มาค่ะ เรามีวิธีที่จะหาค่า SD จากค่า 95%CI รึเปล่าคะ พอดีว่าจะเอาค่านั้นมาคำนวนหาค่า sample size ค่ะ
ขอบคุณค่ะ
สวัสดีครับ คุณ vanda
ขอบคุณค่ะ อ.wwibul
ชอบกระทู้แบบนี้จังเลยค่ะ จะได้มีที่แลกเปลี่ยน และถามได้ค่ะ
อ่านแล้วชอบมากเลย สนุกและเข้าใจได้ง่ายขึ้น ขอบคุณมากนะคะ ชอบ ชอบ ชอบ