
การประยุกต์สถิติเพื่อการวิจัยทางสารสนเทศศาสตร์ (ตอนที่ 3)
สรุปจากการไปฟังบรรยายและฝึกอบรมเรื่อง – การประยุกต์สถิติเพื่อการวิจัยทางสารสนเทศศาสตร์ ซึ่งทางหลักสูตรสารสนเทศศาสตร์ มสธ. จัดขึ้น เมื่อวันเสาร์-อาทิตย์ที่ 25-26 พฤษภาคม 2556 โดยมี รศ.พวา พันธุ์เมฆา เป็นวิทยากรผู้สอน
(เล่าต่อจาก ตอนที่ 1 และ ตอนที่ 2 )
ข้อมูลที่รวบรวมมาใช้ในการวิจัย แบ่งเป็น 4 ระดับ
- ระดับนามบัญญัติ (Nominal scale) สัญลักษณ์หรือตัวเลขที่กำหนดขึ้น เพื่อใช้แยกแยะสิ่งวิจัยออกจากกัน เช่น 1=ชาย 2=หญิง ตัวเลขไม่สามารถนำมาบวก ลบ คูณ หาร ทำได้แต่การแจงนับจำนวนเป็นความถี่เท่านั้น
- ระดับเรียงอันดับ (Ordinal scale) ตัวเลขที่บอกถึงอันดับมากน้อย รู้ว่าใครดีกว่าใครเท่านั้น แต่ไม่ทราบว่าแต่ละช่วงห่างกันเท่าไหร่ เช่น ระดับการศึกษา ผลการเรียน ความเก่ง สอบได้ที่ 1, 2, 3 ไม่สามารถบอกได้ว่าเก่งกว่ากันเท่าไหร่ เอาตัวเลขไปหาค่าเฉลี่ยไม่ได้ แต่สามารถนำมาบวกหรือลบกันได้
- ระดับอันตรภาค หรือระดับช่วง (Interval scale) ตัวเลขที่นำมาจัดอันดับได้ ความแตกต่างระหว่างอันดับเท่ากัน สามารถนำตัวเลขมาเปรียบเทียบกันได้ว่าว่ามีปริมาณมากน้อยเท่าใด แต่ไม่สามารถบอกได้ว่าเป็นกี่เท่าของกันและกัน เพราะไม่มีศูนย์ที่แท้จริง ข้อมูลนำไปหาค่าเฉลี่ยได้ นำมาบวก ลบ คูณ หรือหารกันได้ เช่น คะแนนสอบ อุณหภูมิ 0, 1, 2, 3 องศา (อุณหภูมิ 0 องศา ไม่ได้แปลว่า ไม่มีความร้อน)
- ระดับอัตราส่วน (Ratio scale) กำหนดค่าตัวเลขให้กับสิ่งที่ต้องการวัด มีศูนย์แท้ ใช้คำนวณได้ทุกรูปแบบ สามารถนำตัวเลขมาบวก ลบ คูณ หาร หรือหาอัตราส่วนกันได้ เช่น น้ำหนัก ความสูง ความยาว (เช่น ถนน 50 กิโลเมตร ยาวเป็น 2 เท่าของถนน 25 กิโลเมตร)
สถิติที่ใช้ในการวิเคราะห์ข้อมูล
- สถิติบรรยาย หรือสถิติพรรณนา ใช้บอกลักษณะ เช่น สิ่งที่ต้องการศึกษามีสัดส่วนเป็นเท่าใดของทั้งหมด (ค่าร้อยละ) สิ่งที่ต้องการศึกษาส่วนใหญ่มีลักษณะอย่างไร (ใช้สถิติวัดแนวโน้มเข้าสู่ส่วนกลาง เช่น mean, median, mode) มีความแตกต่างกันภายในกลุ่มของสิ่งที่ต้องการศึกษามากน้อยแค่ไหน (ใช้สถิติวัดการกระจาย เช่น การกระจายของค่าเฉลี่ย (Mean deviation) ค่าความแปรปรวน (Variance) ส่วนเบี่ยงเบนมาตรฐาน (Standard deviation หรือ S.D.))
- การนำเสนอตารางแสดงข้อมูลส่วนตัวหรือตัวแปรต้นของกลุ่มตัวอย่าง เป็นจำนวน และร้อยละ -- ควรแสดงเป็น “ตารางไขว้” จะเห็นภาพได้ชัดเจนขึ้น
- ค่าเฉลี่ย (Mean) ส่วนเบี่ยงเบนมาตรฐาน (S.D.) ใช้วิเคราะห์ตัวแปรตาม ที่เป็นความคิดเห็นจากแบบสอบถามที่ตอบแบบมาตรประมาณค่า 5 ระดับ — การนำเสนอตารางให้แสดงผล mean, S.D. และการแปรผล การแปลความหมายของค่าเฉลี่ยนิยมใช้แบบอิงเกณฑ์ ต้องมีเกณฑ์กำหนดว่าจะแปลอย่างไร (เช่นแบ่งเป็น 3 ระดับ ได้แก่ 1.00-2.00 = น้อย 2.01-4.00 = ปานกลาง 4.01-5.00 = มาก หรือแบ่งเป็น 5 ระดับ ได้แก่ 1.00-1.49 = น้อยที่สุด 1.50-2.49 = น้อย 2.50-3.49 ปานกลาง 3.50-4.49 มาก 4.50-5.00 มากที่สุด) สำหรับในกรณีที่ข้อใดมีค่า S.D. สูงกว่า 1.20 จะต้องอ่านด้วยว่า ข้อนั้นมีความแตกต่างในกลุ่มสูง หรือกลุ่มตัวอย่างมีความคิดเห็นไม่พ้องต้องกัน
- สถิติอนุมาน หรือสถิติที่ใช้ทดสอบสมมุติฐาน ได้แก่ สถิติทดสอบเกี่ยวกับจำนวนหรือความถี่ (Chi square) สถิติทดสอบนัยสำคัญของค่าสัมประสิทธิ์สหสัมพันธ์ว่า คุณลักษณะต่างๆของสิ่งที่ศึกษามีความสัมพันธ์กันจริงหรือไม่อย่างไร (ค่าสหสัมพันธ์ Correlation) สถิติทดสอบค่าเฉลี่ย กลุ่มตัวอย่าง 2 กลุ่ม (t-test สำหรับกลุ่มตัวอย่าง < 30 หรือ Z-test สำหรับกลุ่มตัวอย่างเท่ากับหรือ > 30) สถิติวิเคราะห์ความแปรปรวน (Analysis of Variance : ANOVA) และสถิติการวิเคราะห์การถดถอย (Regression analysis)
- การทดสอบความแตกต่างระหว่างค่าเฉลี่ย ที่กลุ่มตัวอย่าง 2 กลุ่ม เกี่ยวข้องกันหรือเป็นกลุ่มเดียวกัน (t-test dependent) ใช้กับการวิจัยเชิงทดลอง มีการเปรียบเทียบคะแนนก่อน-หลังการทดลอง ภายในกลุ่ม N เดียวกัน ควรตั้งสมมุติฐานแบบมีทิศทาง (เช่น ได้คะแนนดีขึ้นหลังการทดลอง) แสดงผลก่อนและหลังการทดลองเป็นค่า N, Mean, S.D. แล้วสั่งโปรแกรม SPSS คำนวณค่า t ให้ — จากนั้น นำค่าระดับแห่งความเป็นอิสระ (degree of freedom : df) = N-1 ไปเปิดตารางค่าวิกฤต Critical value of t และดูว่า ที่ระดับนัยสำคัญ (level of significance) 0.05 มีค่า t เท่าไหร่ — ถ้าค่า t ที่คำนวณได้สูงกว่าค่า t ในตารางวิกฤต แสดงว่า ผลการทดลองสอดคล้องกับสมมุติฐานที่ตั้งไว้ อย่างมีนัยสำคัญทางสถิติที่ระดับ 0.05
- การทดสอบความแตกต่างระหว่างค่าเฉลี่ย ที่กลุ่มตัวอย่าง 2 กลุ่ม ไม่เกี่ยวข้องกัน (t-test independent ) ใช้กับกลุ่มตัวอย่างที่มีลักษณะไม่เหมือนกัน เช่น ชาย-หญิง วุฒิการศึกษาปริญญาตรี-ปริญญาโท กลุ่มควบคุม-กลุ่มทดลอง แสดงผลทั้งสองกลุ่มเป็นค่า N, Mean, S.D. แล้วสั่งโปรแกรม SPSS คำนวณค่า t ให้ — จากนั้นเปิดตารางค่าวิกฤต Critical value of t โดยดูว่าเป็นการทดสอบแบบ 2 ทาง (two-tail test) คือกลุ่มตัวอย่าง 2 กลุ่มไม่เกี่ยวข้องกัน หรือแบบทางเดียว (one-tail test) คือกลุ่มตัวอย่าง 2 กลุ่มเกี่ยวข้องกันหรือเป็นกลุ่มเดียวกัน — นำค่าระดับแห่งความเป็นอิสระ (degree of freedom : df) = (n1+n2)-2 ไปเปิดตารางค่าวิกฤต Critical value of t และดูว่า ที่ระดับนัยสำคัญ (level of significance) 0.05 (หรือจะใช้ 0.1 ก็ได้ ถ้าเป็นสาขาทางการแพทย์) มีค่า t เท่าไหร่ ถ้าค่า t ที่คำนวณได้ ต่ำกว่าค่า t ในตารางวิกฤต แสดงว่า ผลการทดลองในกลุ่มควบคุมและกลุ่มทดลอง แตกต่างกันอย่างไม่มีนัยสำคัญทางสถิติ หรือไม่แตกต่างกันนั่นเอง
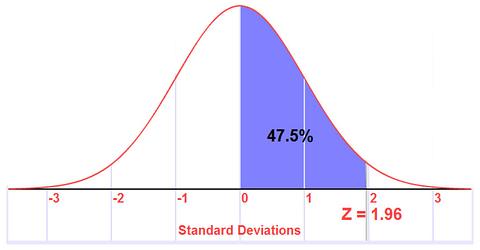
[ อ่านต่อ ตอนที่ 4 ]
คำสำคัญ (Tags): #สถิติการวิจัย#การวิจัยทางสารสนเทศศาสตร์
หมายเลขบันทึก: 537246เขียนเมื่อ 27 พฤษภาคม 2013 11:10 น. ()ความเห็น (1)
ขอบคุณค่ะ น้องซิลเวียกำลังเรียนวิชา Statistics ในเทอมนี้พอดีค่ะ