
2x2 table by OpenEpi, STATA, Stratified Analysis และเปรียบเทียบ 2x2 table กับ Venn diagram
"Two by two tables are used to evaluate the association between a possible risk factor ('Exposure') and an outcome ('Disease'). Counts summarizing the occurence of the four possible combinations of events in the study population are entered into the appropriate cells. "
| Dis (+) |
Dis (-) | |
| Exp (+) |
44 | 11 |
| Exp (-) |
22 | 33 |
http://www.openepi.com/v37/TwobyTwo/TwobyTwo.htm
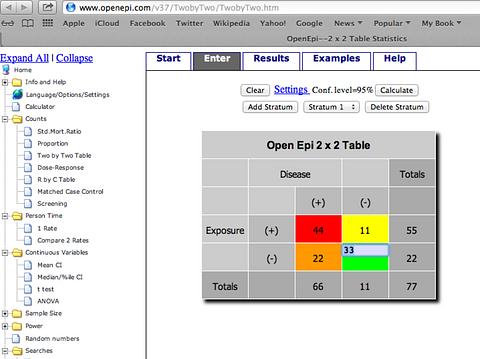
ใส่ตัวเลข 44, 11, 22, 33 เรียงลำดับจากซ้ายไปขวาและบนลงล่าง
และต้องกดปุ่ม Calculate 2x2 Table จึงจะรับค่า input 33
(ปุ่ม Add Stratum อธิบายอยู่ตอนท้ายบทความ)
Cross-sectional Study ใช้ 2x2 table คำนวณค่า Chi Square
การสำรวจหมู่บ้าน
บ้านมีคนเมาหรือไม่ ? Dis (+) มีคนเมา, Dis (-) ไม่มีคนเมา,
บ้านมีขวดโซดาหรือไม่ ? Exp (+) มีขวดโซดา, Exp (-) ไม่มีมีขวดโซดา
จำนวนบ้านที่มีขวดโซดาและมีคนเมา = a
จำนวนบ้านที่มีขวดโซดาและไม่มีคนเมา = b
จำนวนบ้านที่ไม่มีขวดโซดาและมีคนเมา = c
จำนวนบ้านที่ไม่มีขวดโซดาและไม่มีคนเมา = d
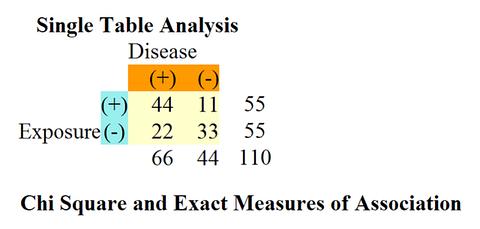
| เมา | ไม่เมา | |
| มีขวดโซดา | 44 | 11 |
| ไม่มีขวดโซดา | 22 | 33 |
http://www.openepi.com/v37/TwobyTwo/TwobyTwo.htm
a = 44, b = 11
c = 22, d = 33
Ho :การพบขวดโซดาและการเมาเป็นอิสระต่อกัน (ไม่มี Association)
Ha :การพบขวดโซดาและการเมาไม่เป็นอิสระต่อกัน (มี Association)
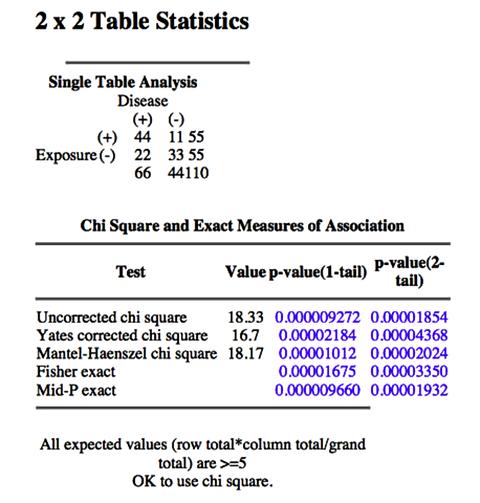
Chi Square = 18.33 p-value (2-tail) = 0.000018
จึงปฏิเสธ Ho
มี Association ระหว่างการพบขวดโซดาและการเมา
Association คือการเกี่ยวข้องเกี่ยวเนื่องกัน ในที่นี้เป็นแบบ Positive Association
คือบ้านที่พบขวดโซดามากก็พบคนเมามาก บ้านที่พบขวดโซดาน้อยก็พบคนเมาน้อย
แต่การมี Association ไม่ได้หมายถึง การเป็นสาเหตุ Association อาจไม่ใช่สาเหตุ
การวัด Exposure และ Outcome ในช่วงเวลาเดียวกัน
ไม่สามารถบอกได้ว่า Exposure เกิดขึ้นก่อน Outcome หรือไม่
ต่างกับ Cohort, Case Control, Experimental ซึ่งบอกได้ว่า Exposed เกิดขึ้นก่อน Outcome
การที่จะสรุปว่า Association เป็นสาเหตุ ยังจะต้องมีเหตุผลสนับสนุนอื่นๆ อีกหลายข้อ
Link to: Causal Association http://www.gotoknow.org/posts/203606
Cross -sectional Study เปรียบเหมือนการถ่ายภาพแบบ Snap-Shot ของเหตุการณ์
สามารถหาค่าความชุก (Prevalence) ของโรค
Prevalence = (จำนวนป่วยรายใหม่ + จำนวนป่วยรายเก่า) / (จำนวนประชากรกลุ่มเสี่ยง)
======================================================
| Dis(+) | Dis(-) | ||
| Exp(+) | 44 | 11 | 55 |
| Exp(-) | 22 | 33 | 55 |
ตาราง 2x2 อันเดียวกันนี้ และตัวเลขเดียวกัน ถ้าเป็นเรื่องราวของ Cohort
จะสามารถคำนวณค่า Risk Ratio และ 95% Confidence Interval
Cohort Study คำนวณค่า Risk Ratio
Cohort Study เรื่มต้นจากกลุ่มที่แข็งแรงดี 2 กลุ่ม ต่อมาอีก 5 ปี ตรวจพบโรคถุงลมโป่งพอง
กลุ่มสูบบุหรี่ 55 คน พบว่าป่วย 44 คน ไม่ป่วย 11 คน
กลุ่มไม่สูบบุหรี่ 55 คน พบว่าป่วย 22 คน ไม่ป่วย 33 คน
ถาม Risk Ratio มีค่าเท่าไร
Risk_1 = 44 / (44 + 11)
Risk_2 = 22 / (22 + 33)
Risk Ratio = (Risk_1) / (Risk_2)
Risk Ratio = (44 / 55) / (22 / 55) = 2
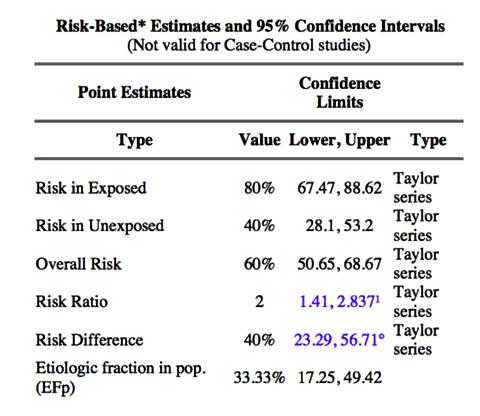
Risk Ratio = 2
95% Conf. Interval 1.41 to 2.83
Cohort Study จะหาค่าอุบัติการ (Incidence) ของโรคได้
Incidence = (จำนวนป่วยรายใหม่) / (จำนวนประชากรกลุ่มเสี่ยง)
เนื่องจาก Cohort ทั้งสองกลุ่ม เริ่มจากยังไม่ป่วยจนกระทั่งพบว่าเริ่มป่วยรายใหม่
======================================================
| Dis (+) | Dis (-) | |
| Exp (+) |
44 | 11 |
| Exp (-) |
22 | 33 |
| 66 | 44 |
ตาราง 2x2 ตัวเลขเดียวกันนี้ ถ้าหากเป็นเรื่องราวของ Case Control
จะสามารถคำนวณค่า Odds Ratio และ 95% Confidence Interval
Case Control Study คำนวณค่า Odds Ratio
Case Control เรื่มต้นที่ Case คือ โรคถุงลมโป่งพอง
Case 66 คน ก่อนนี้เคยสูบบุหรี่หรือไม่ ? สูบบุหรี 44 คน, ไม่สูบ 22 คน
Control 44 คน ก่อนนี้เคยสูบบุหรี่หรือไม่ ? สูบบุหรี 11 คน, ไม่สูบ 33 คน
ถาม Odds Ratio มีค่าเท่าไร
ก่อนนี้เคยสูบบุหรี่หรือไม่ ? Odds = (Probability that it happen) / (Probability that it does not)
| ป่วย | ไม่ป่วย | |
| สูบบุหรี่ | 44 | 11 |
| ไม่สูบบุหรี่ | 22 | 33 |
Odds_1 = 44 / 22
Odds_2 = 11 / 33
Odds Ratio = (Odds_1) / (Odds_2)
Odds Ratio = (44 / 22) / (11 / 33) = (2 / 1) / (1 / 3) = 6
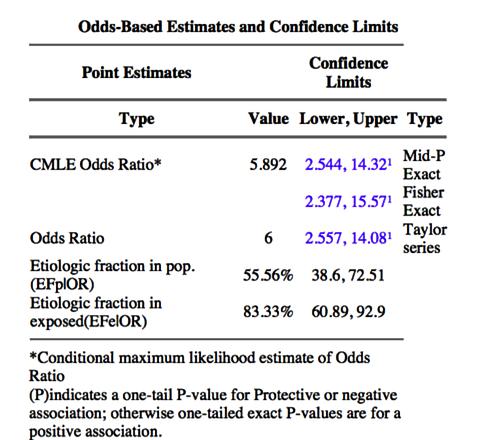
Odds Ratio = 6
95% Conf. Interval 2.55 to 14.08
======================================================
เมื่อใส่ค่า a,b,c,d แล้วกดปุ่ม Calculate
2x2 Table จะคำนวณค่าสถิติทั้ง 3 แบบในคราวเดียว
เลือกใช้การคำนวณแบบใดแบบหนึ่งให้ตรงกับลักษณะของงานวิจัย
Cross-sectoinal หรือ Cohort (Risk based) หรือ Case Control (Odds Based)
=====================================================
โปรแกรมสถิติ STATA
Default ของ Openepi เป็นแบบ Exposed อยู่ด้านซ้าย ของ Table
(สามารถ set ให้ Exposed อยู่ด้านบนได้)
แต่ STATA Exposed อยู่ด้านบน ของ table จึงจัดเรียงลำดับตัวเลขใหม่
คำสั่งสำหรับ Cross-sectional, Cohort และ Case Control คือ
tabi 44 22 \ 11 33, chi2
csi 44 22 11 33
cci 44 22 11 33
======================================================
นอกจากการคำนวณ ตาราง 2x2 table เพียงตารางเดียว
อาจจะคำนวณ 2 ตารางพร้อมๆ กัน โดยคำนวณแยกกันแต่ละตาราง,
รวม 2 ตารางแบบ Crude, และ M-H Adjusted
ซึ่งใน OpenEpi จะใช้คำสั่ง "Add Stratum"
ส่วน STATA สั่งงานที่หน้าต่าง "dot command"
ซึงการรวมกันแบบ Crude บางครั้งได้ผลกลับทิศทางกับเมื่อก่อนที่จะนำมารวมกัน
ถ้าได้ข้อมูลแบบที่รวมกันมาแบบ Crude ก็นำแยกวิเคราะห์แต่ละกลุ่ม
แต่ละกลุ่มมีค่า Odds Ratio, Risk Ratio แตกต่างจาก
ค่าเดิมที่รวมๆ กันมาแล้ววิเคราะห์หรือไม่ เรียกว่า Stratified Analysis
บทความเรื่อง Simpson's Paradox การรวม 2 table Green, Blue, Fit, Not Fit
Link to: http://www.gotoknow.org/posts/499018

การรักษานิ่วในไต วิธี A (Open Surgery) วิธี B (ESWL)
1) นิ่วก้อนเล็กวิธี A ดีกว่า
2) นิ่วก้อนใหญ่วิธี A ดีกว่า
3) ถ้ารวมกันทั้งนิ่วก้อนเล็กและใหญ่ วิธี B ดีกว่า ?
4) M-H Adjusted Odds Ratio วิธี A ดีกว่า
M-H Adjusted Stratified Analysis จะแสดงให้เห็นว่า มี Confounder หรือไม่?
มี Effect Modification หรือไม่? สาเหตุเกิดจาก นิ่วก้อนเล็กและก้อนใหญ่
ได้รับการรักษาด้วย วิธี A และฺวิธี B โดยมีอัตราส่วนที่ไม่เท่ากัน
Link to: http://www.gotoknow.org/posts/439144
Link to: http://www.ncbi.nlm.nih.gov/pmc/articles/PMC1339981/?tool=pmcentrez
======================================================
2x2 Table เปรียบเทียบกับ Venn Diagram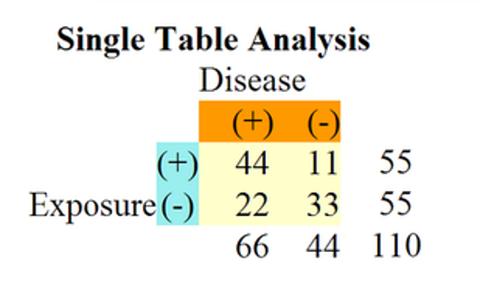
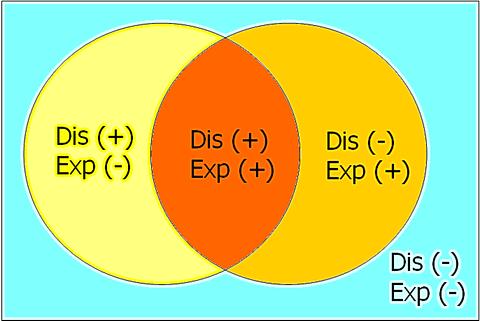
Venn diagram
"A Venn diagram or set diagram is a diagram that shows all possible logical relations between a finite collection of sets. Venn diagrams were conceived around 1880 by John Venn. They are used to teach elementary set theory, as well as illustrate simple set relationships in probability, logic, statistics, linguistics and computer science."
http://en.wikipedia.org/wiki/Venn_diagram
ความเห็น (0)
ไม่มีความเห็น