
สถิติทางการแพทย์แบบบ้านๆ : Inferential statistic
Inferential statistic เกิดจากความพยายาม generalize
"ผลที่ได้"(observed value) จากกลุ่มตัวอย่างไปสู่
" ความเป็นจริง" (True
value) ในกลุ่มประชากรเป้าหมาย
หากเราต้องการแค่รู้ว่า
จำนวนผู้ป่วยความดันสูงในวอร์ดเราเท่ากับ? คำถามนี้ ไม่ต้องใช้
inferential statistic หากเราไม่ต้องการ generalize
ค่าความดันนี้ว่าเป็นของผู้ป่วยในวอร์ดอื่นๆ ด้วย
Inferential statistic มีหลักการคร่าวๆ คือ
ค่าที่ได้จากการสุ่ม 1 ครั้ง -> ใช้การกระจายความน่าจะเป็น
ว่าถ้าสุ่มหลายๆๆๆครั้งจะเป็นอย่างไร -> ตัดสินใจเลือกผล
"ที่เชื่อว่า" เป็นผลจริงของประชากร
ลองทำความเข้าใจด้วยการเปรียบเทียบกับกระบวนการตัดสินของศาล
1. ตั้ง
Hypothesis : มีนัยยะของการเปรียบเทียบ ผลที่ได้จาก
sample ครั้งนี้ว่าตรงกับ "ความจริง" หรือไม่เสมอ
ทำไมต้อง Null vs Alternative
hypothesis?
ศาลจะถือว่า จำเลยยังไม่มีความผิด หรือ
"ไม่ต่างจากประชาชนทั่วไป" (Null
hypothesis) ไว้ก่อน
จนกว่าจะมีหลักฐานพยานเพียงพอ..จึงจะสรุปว่ามีความผิดกี่กระทงก็ว่าไป
( Alternative hypothesis) หลักฐานแค่ไหนจะพอเพียง ก็ขึ้นกับจำนวนพยาน
(sample size) ความผิดนั้นจะแจ้งเพียงไร (Effect
size) พยานแต่ละคนให้ข้อมูลตรงกันแค่ไหน
(Variation)
2.
ตั้งระดับ "acceptable" type I - false positive ,
typeII - false negative : ในการตัดสินใดๆ
ตั้งแต่การตัดสินลำหน้าในฟุตบอล ไปจนถึงการตัดสินคดีสำคัญในศาล
ล้วนมีโอกาสผิดอยู่สองแบบ คือ
- จริงๆ แล้วไม่ผิดแต่ตัดสินว่าผิด = type I หรือ alpha
- จริง ๆแล้วผิด แต่ตัดสินว่าไม่ผิด (รอดสายตาไป) = type II
หรือ beta
3. เลือก statistical
test:
ขั้นต่อไปคือการเลือกทีมผู้พิพากษา คณะลูกขุน ซึ่งก็คือการเลือก
model ของ Probability distribution นั่นเอง. ตัวอย่างเช่น
Probability distribution of sample "mean" คือ t-distribution ที่
adjust รูปร่างไปตามขนาด sample size, จนถ้า sample size ใหญ่พอ
(>120) รูปร่างคงตัวเป็น normal z -distribution
Probability distribution of sample"proportion" คือ binomial
distribution สำหรับ sample size เล็ก กับ poisson distribution
สำหรับ sample size ใหญ่ๆ --หรืออีกเทคนิคคือ Chi-squre
distribution
Probability distribution of sample "within and between varience
ratio" ( สำหรับ ANOVA)" คือ F-distribution ...
เป็นต้น
4. พิจารณาผลจาก
statistic test ได้แก่ p value ซึ่งเป็น "qualitative
judgement based on chance" กับ confident interval ซึ่งเป็น
"quantitatvie judgement based on precision"
P-value
คืออะไร? มีนิยามอย่างเป็นทางการคือ "
probability of obtaining value atleast extreme as
the observed value , if null hypothesis is true" อ่านรวมๆ
แล้วงงกว่าเดิม ต้องแยกที่ละส่วนคะ
สังเกตได้ว่าประโยคแรกกับประโยคหลังขัดกัน
อาจพูดเป็นภาษาเปาบุ้นจิ้นว่า "โอกาสที่จะพบพฤติกรรมเลวร้ายเยี่ยงนี้
(หรือยิ่งกว่านี้), หากจำเลยไม่มีความผิด"
ง่ายกว่านั้นคือ " โอกาสตัดสินว่าเป็นโรค ทั้งๆ ที่ไม่มีโรค"
หากชอบคิดลัด Pvalue = "False positive rate
ที่ได้จริง" ซึ่งจะนำไปเทียบกับ
alpha
ซึ่งเป็นระดับที่ตั้งขึ้นมาว่า "False positive rate
ขนาดที่รับได้" ถ้าตั้ง alpha ไว้ที่ 0.05 แต่ p value
ออกมา 0.10 เราก็ต้องสงวนท่าที ยังไม่ตัดสินว่าผิด เนื่องจาก false
positive ที่ได้เกินกว่าจะรับได้
การตีความ False positive rate หมายถึง ถ้าตัดสินคน"บริสุทธิ" ไป 100 คนพลาดเอาเข้าคุก 5 คนก็พอรับไหว ...ซึ่งต่างจาก ทุก 100 คนคุก (ทั้งผิดและบริสุทธิ์) เป็นคนบริสุทธิ 5 คน -- ต่างกันอย่างไร..สมมติว่า ปีหนึ่งศาลตัดสิน 400 คดี เอาเข้าคุก 100 คดี เมื่อคิดตามกรณีแรก คนบริสุทธิโดนเป็นจำเลย 10 คนจึงไม่มีใครพลาดเข้าคุกเลย แต่ถ้าคิดตามกรณีหลังหมายถึงมีคนบริสุทธิเข้าคุกปีละ 5 คน - มากไปแล้ว!!
ไม่ได้แปลว่า โอกาสที่ผลจริงๆ "ไม่ต่าง" 5 %
สรุปคือ p value อยู่ในตระกูล specificity เราจึงไม่สามารถแปลผลแบบตระกูล PPV
Confident interval คืออะไร? x%
CI ทำหน้าที่บอก "Precision ณระดับ alpha 0.0X"
เราคุ้นเคยกับ 95% CI เพราะเรานิยมตั้ง alpha ไว้ที่ 5%
(0.05) ถ้าตั้ง alpha ไว้น้อยกว่านี้เช่น 0.002 (เช่นกรณี
multiple comparison) ก็จะเปน 99.8% CI
นิยามที่เหมาะสมของ 95% CI คือ 95% of this "range" of
interval will contain the population value..
ที่มาของ 95% CI มีกระบวนการสร้างคือ
1. หา Sample หนึ่งที่มีจำนวน n : ประมาณค่า 95% CI ของ
sample นี้ได้จาก
Mean +/- 1.96 X Standard error of mean
1.96 ตัวคูณจากการกระจายแบบ noraml
( z-distribution)
Standard error of mean (SEM) =
population standard
deviation (sigma)
square root of n
เนื่องจากส่วนมาก เราไม่รู้การกระจายของประชากร
ค่า sigma จึงทดแทนด้วย sample standard
deivation (SD)..หมายความว่า เรากะว่าการกระจายของ sample
น่าจะใกล้เคียงกับของประชากร
แต่ในกรณี sample เล็กกว่า 120 การใช้ SD ทดแทน
sigma ยิ่งมีความคาดเคลื่อนสูง เป็นที่มาของ
student-t ซึ่งใช้หลัก adjust ตัวคูณหน้า SEM
ตาม df
สมมติว่า n =20, ตัวคูณหน้า SEM จะไม่ใช่ 1.96
หากเป็น 2.093 แทน
Note * 95%CI ควรจำว่า
mean +/- 1.96 X SEM
ไม่ควรจำว่า mean +/- 1.96
X SD
2. sampling ครั้งละ n จนครบ 100
ครั้ง, จะพบว่า CI เป็นที่ได้มาจาก sampling แต่ละครั้งใน
population หนึ่งจะมี ความยาวของช่วง (range) เท่ากัน
แม้ว่าค่าตัวแทนหรือค่ากลางของแต่ละครั้งไม่ตรงกัน
3. แม้ค่ากลางของ sampling แต่ละครั้งไม่ตรงกัน แต่เมื่อใช้หลักการของ
central limit theorem เรา"เชื่อ" ว่า ค่ากลางของประชากร
ประมาณได้จาก
การดูภาพรวมของหลายๆ sample ดังนั้นจึง "เชื่อ" ว่า
95 ใน 100 ของ sampling range ครอบคลุมค่ากลางของประชากร
95% CI จึงหมายถึงมี 5% ของ range นี้ไม่ครอบคลุมค่าที่ "เชื่อ"ว่าเป็นค่ากลางของประชากร แต่ ไม่ได้แปลว่า โอกาสที่ค่ากลางของประชากรอยู่นอก range นี้คือ 5% (จินตนาการ ค่าจริง มีอยู่ค่าหนึ่งที่ fixed แต่จริงๆ เราไม่รู้ว่า probability ที่ค่าจริงจะอยู่ใน range เท่าไหร่ --> ยกตัวอย่าง ถ้าเราไม่สามารถใช้ central limit theorem assumptin ได้ ค่ากลางของประชากรจริงๆ อาจไม่ใช่ค่าที่เรา "เชื่อ" นี้ก็ได้)
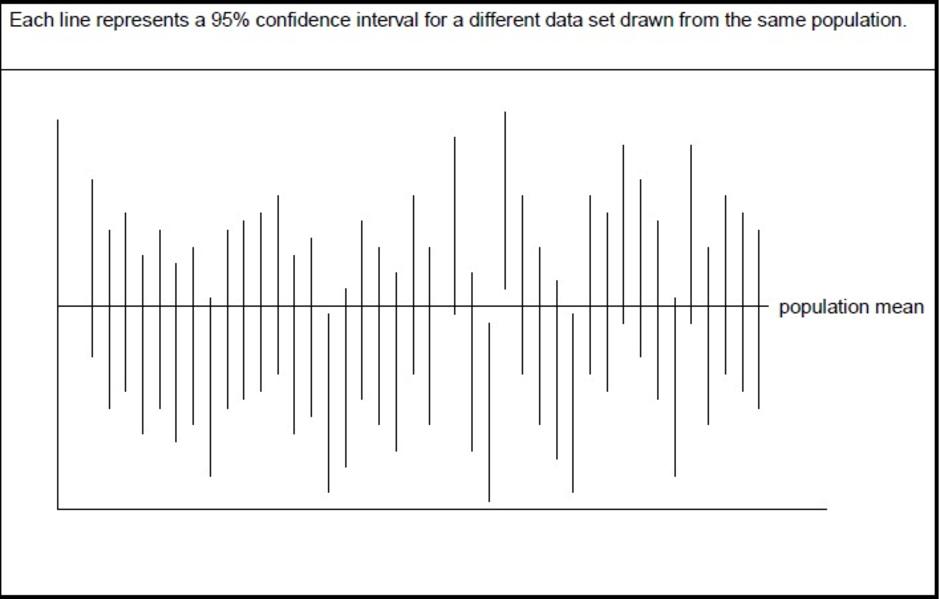
ภาพจาก Elliott Sober;What does a confidence interval mean?
จากภาพจะเห็นว่าแม้ 95% CI มี range คร่อม 0 หรือ 1 แต่ค่าอื่นๆ
ที่ range ไปถึง ก็ยังมี "โอกาส" เป็นไปได้
ทำให้นึกถึง pitfall การรายงานผลวิจัย ที่ Peter Bacchetti เรียกว่า
"p value fallacy"
หมายถึงการให้ความสำคัญกับ p-value เพียงอย่างเดียว
เป็นตัวชี้เป็นชี้ตายว่า study negative หาก p>0.05
ทั้งที่ควรพิจาณาจาก 95% CI มากกว่า
ยกตัวอย่าง p = 0.13 95% CI of RR = 0.9 - 13.0 ->
หากดูแต่ p value แล้วแปลว่า "No statistical significant diffrent"
in risk หรือ "No evident of
different" ระหว่างยาใหม่กับยาเก่า คำถามคือ Range
ที่ค่อนไปทางเพิ่ม risk และ range ของค่าที่ก็โอกาสเป็นไปได้คือเพิ่ม
risk ตั้ง 13 เท่าละ?
และเมื่อผลวิจัยถูกนำไปตีพิมพ์โดยสื่อที่ไม่เข้าใจสถิติการแพทย์
ก็จะกลายเป็น "No
different" คำเดียว เป็นการสร้างความเข้าใจผิดในวงกว้าง
กรณีนี้จึงแนะนำให้ใช้ประโยค The study "suggests" increase risk
"but" did not reach statistical significant.( 95%CI is too wide to
conclude of no effect) สามารถทดลองใช้ interactive
result interpretation โดย Bacchetti ได้ที่นี่คะ
ความเห็น (0)
ไม่มีความเห็น